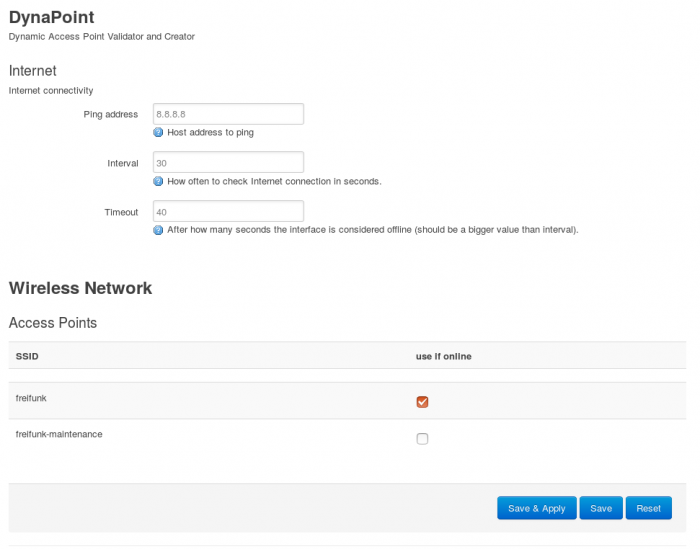
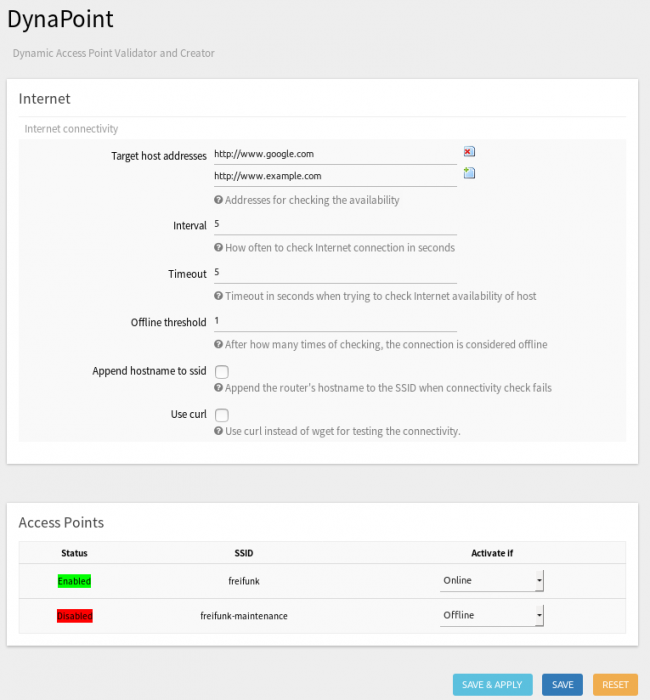
Hello again, for two months I have been working on my project and I have achieved all the goals.
An alpha version of my program was released for the mid-term evaluation.Since then I have fixed all the bugs, packaged the program for OpenWRT, tested the code and written the documentation.
Everything is available on the GitHub repository [0]
I structured my work opening by issues for all the bugs I had to fix and for everything I wanted to improve. Then, I organized the issues in milestones. Milestone 0.1 [1] is the one that I had to complete to finish the project. When that milestone was closed I made the branch “v0.1” [2].
Tests
In order to be sure that my program worked correctly. I wrote a simulator in python. It’s made by a small server, with the same interface as OONF’s telnet plugin, and two python libraries written by my mentor: cn_generator [3] and pop-routing[4]. The first one generates synthetic graphs using the Cerda-Alabern[5] algorithm, the second one is a pop-routing implementation in python. In the server I implemented the commands to push the NetJson[6] topology and the ones to receive the timers values.
When prince requests a topology from my test program, cn_generator generates a random graph and pushes it back; meanwhile using the python implementation of pop-routing, the references values are computed. The values received from prince are then compared to ones calculated using python.
The goal of tests is to verify that the difference between the reference and the measured values is always less than 1%.
Measurements
I’m going to use my work to write my Bachelor Thesis, so I wanted to perform some measurements to check how well it worked.
My goal was to implement the algorithm on an embedded device, so I chose to measure the execution time on a “Ubiquiti Picostation M2HP” to see how well it was performing.
I branched Prince [7], modifying the code to measure the time needed to calculate the betweenness centrality and push it back along with the timers.
I used the graph generator to create graphs from 5 to 500 nodes, and I measured the time needed to compute with a sample every 10 nodes. For each sample I ran 5 tests, then calculating the mean and the standard deviation. The results are shown here:

As you can see from the graphic above, the computation time on the embedded device is quite good if we use the heuristic (8s for 100 nodes), it proved to be unusable without it (100s for 100 nodes)
OpenWRT Package
The last objective I gave myself in the previous post was to write a plugin for OLSRd. Since OLSRd isn’t maintained anymore – and since all the developers are working on OONF – I decided to focus on it while avoiding the plugin. Instead, I wrote a makefile and packaged prince for openWRT / LEDE. The makefile hasn’t been published yet in any openWRT feed, but it is hosted in my repository [8]. Instructions are available along with documentation.
Future Work
I’ll keep working on this project, mantaining the code and fixing the future issues. Since the graph-parser library is the last piece of code implemented in C++ and it depends on the Boost libraries, I’m looking forward to re-implement it in pure C.
One of my goals was also to run prince in my WCN (Ninux Firenze), but switching from OLSRd to OONF is taking more time than expected, so I’m hoping to try it in the future.
Gabriel
[0]: https://github.com/gabri94/poprouting/
[1]: https://github.com/gabri94/poprouting/milestone/1?closed=1
[2]: https://github.com/gabri94/poprouting/tree/v0.1
[3]: https://ans.disi.unitn.it/redmine/projects/cn_generator/repository
[4]: https://ans.disi.unitn.it/redmine/projects/pop-routing/repository
[5]: https://pdfs.semanticscholar.org/4ac8/05e7359c6b20c3cdd5da24284d3826b9609c.pdf
[6]: http://netjson.org/
[7]: https://github.com/gabri94/poprouting/tree/exec_time
[8]: https://github.com/gabri94/poprouting/blob/master/Makefile.openwrt

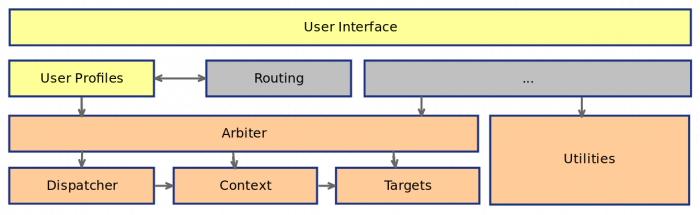
 ). But that should give you an idea of what is to come in the UI department.
). But that should give you an idea of what is to come in the UI department.