Introduction
Hello folks 👋
The past 4 months has been pretty exciting and challenging for me . Me and my mentor Andi Bräu together worked on a cool project called Videoodyssee , with GSoC’22 almost coming to an end in this blog post I wanna share all of my accomplishments , results and little bit about the project.
About Videoodyssee
In 2017 we started our video portal for freifunk at media.freifunk.net. To get videos online we have a more or less complicated upload workflow:
- Upload video file to a processing server.
- Correct video file settings.
- Convert video to target formats.
- upload to CDN and Youtube.
- Publish the video to the media portal.
The previous Videoosyssee system has some problem like
- With current lambdacd pipeline we can’t have multiple workers to enable parallel video processing.
- The current lambdacd pipeline isn’t maintainable anymore and it has got a lot of dependency issues.
- Currently we don’t have any video verification steps in our publishing workflow which leads to publishing of unwanted videos.
So we decided to re-implement the pipeline using a new CI/CD tool and we chose to use the GoCD tool to build the pipeline as it suits better for the video processing pipeline we are looking to build. Later in the project we also decided to re-implement the Videoodyssee uploader using React.
Systems Involved in the project:
1 . Videopipeline : A GoCD server with processing pipeline to process and publish the video.
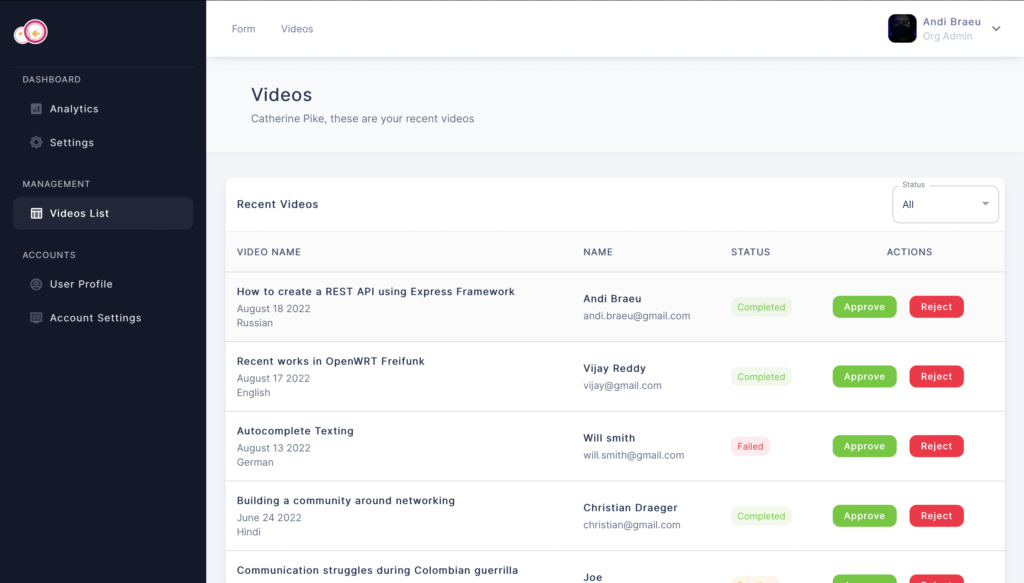
2. Videoodyssee Frontend : A React frontend application for the users to submit the video data and admin dashboard for the admins.
3.Videoodyssee API : A Node.js REST API implemented using Express framework.
Video upload workflow:
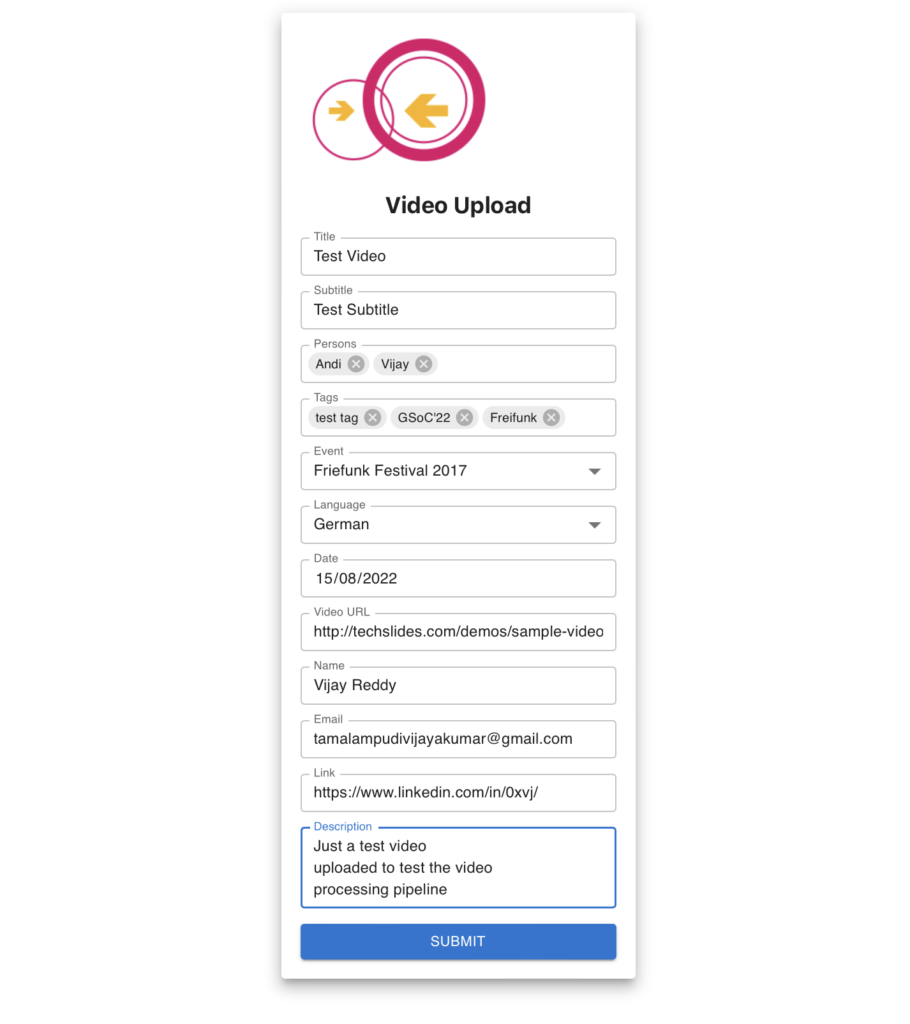
- User submits the details of the video using the video details submission form.
- Admin gets a notification email about the newly submitted video.
- Admins logs in to the Videoodyssee admin dashboard reviews the video and approves it.
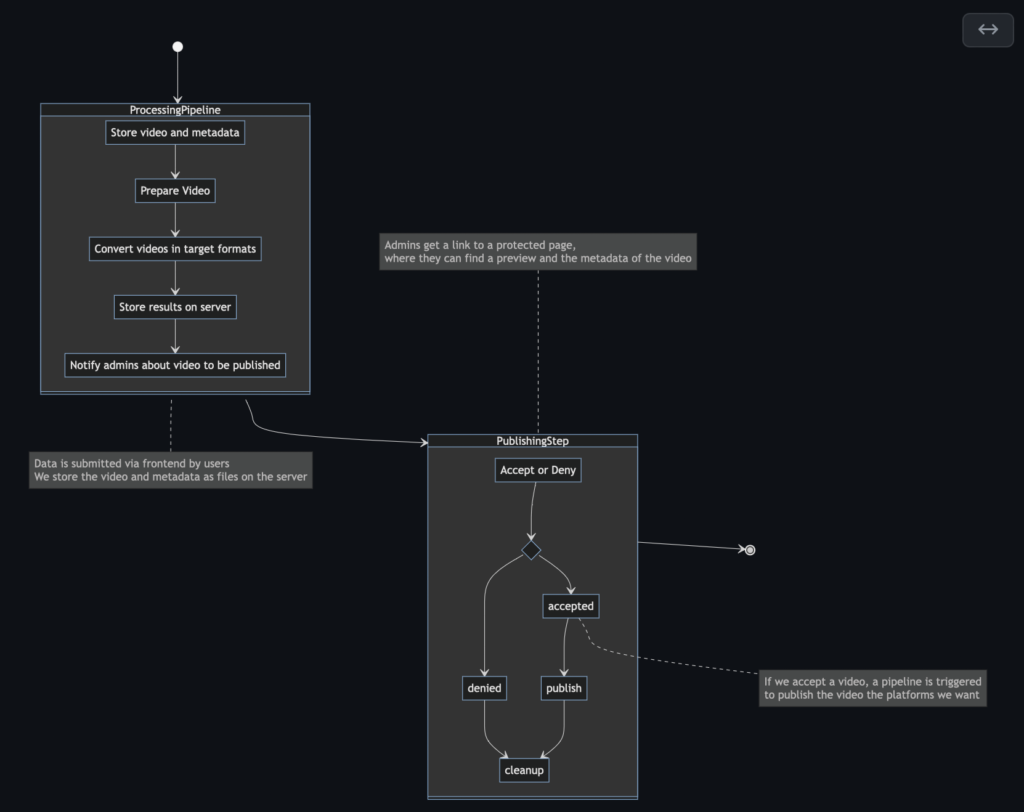
- When the admin approves the video it will trigger the video processing pipeline.
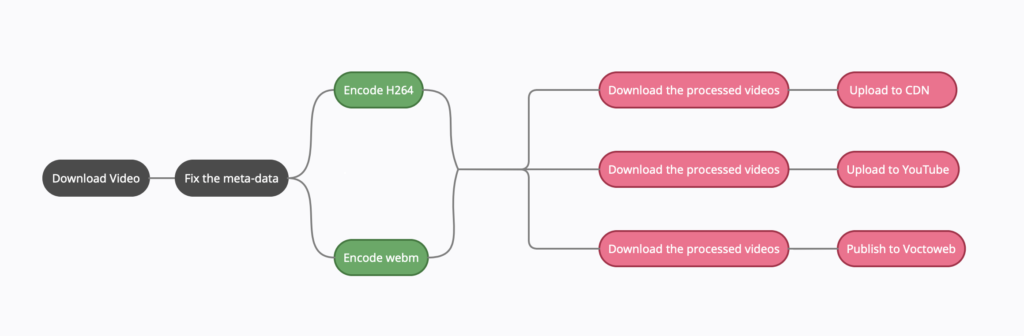
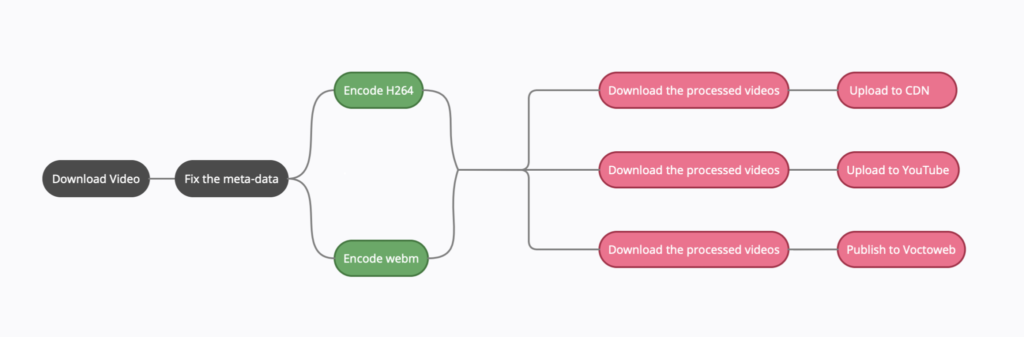
- The processing pipeline will download the video , fixes the video meta-data , encodes the video into webm and h264 formats , generates the thumbnail and timelens data , uploads all the files into the CDN and publishes the video to Voctoweb.
- After the video is published to Voctoweb user will a notification email saying that his got published to the video portal successfully.
Video processing pipeline
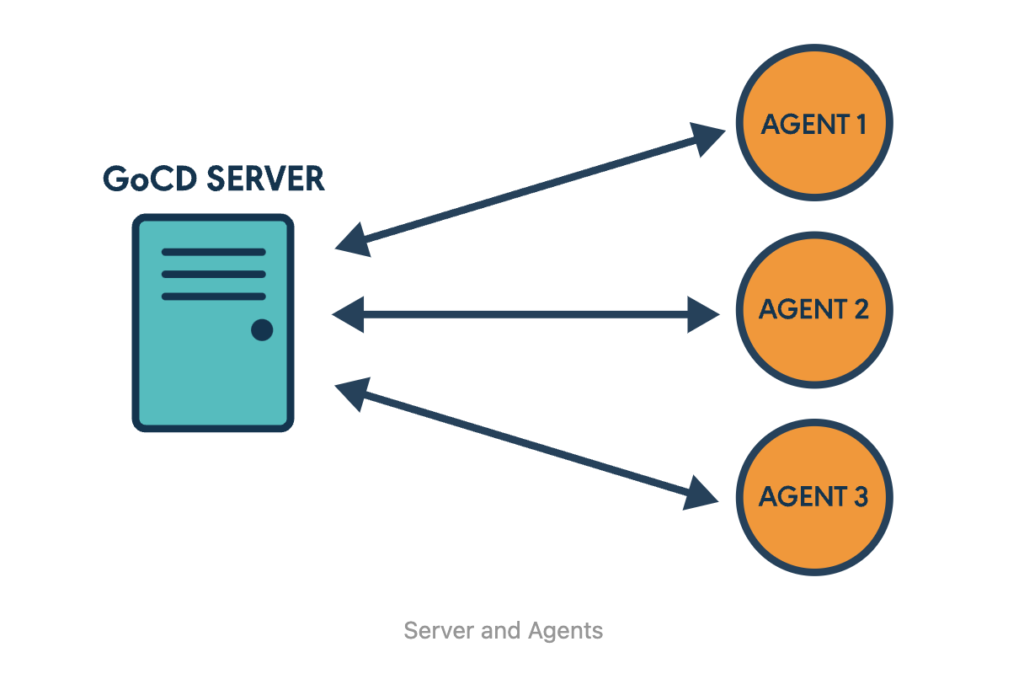
The pipeline is implemented using GoCD , a CI/CD tool as it suits better for the video processing pipeline we are looking to build. The GoCD follows master-slave architecture which consists a Go-Server and multiple Go-Agents.
Go-Server
Go-server acts as a master and is the one that controls everything, assign the jobs to Go-agents and provides the user interface to users of the system.This is where we define the pipelines and trigger the pipelines.Go-server assigns the jobs to the agents which are free and stores the artifacts produced by Go-agents.
Go-Agents
The agents are the ones that do the actual work like processing videos , generating thumbnails and uploading processed videos. We can have N number of agents which we can scale up or scale down according to our needs. So in future if we need to process more number videos at the same time we can increase the number of agents to get the job done.
You can have a look at the video processing pipeline code here. And here is the Videpipeline GitHub repo https://github.com/freifunk/videopipeline .
Tasks accomplished:
- We created a config repo in GitHub to store the pipeline code so that whenever we change the pipeline code GoCD server will automatically pull the changes and builds the new pipeline.
- Implemented the video processing pipeline.
- Modified the pipeline processing scripts to make them work with the new GoCD pipeline.
- Automated the provisioning and deployment of Go-Server and Go-Agents using Ansible. You can have a look at the Ansible playbooks here.
Remaining tasks:
- Automating the pipeline deployment from the GitHub config repo.
- Publish the video to YouTube.
- Notify the admins with an email when a new video is submitted by someone.
- Notify the publisher when his video got approved , processed and published to Voctoweb.
Videoodyssee Frontend
For the users to submit the video details we need a frontend application which takes the data from the user and sends it to the REST API which will eventually trigger the pipeline using the GoCD API to start the video upload workflow.
We chose to use the React to implement the frontend application as it is quick and easy. The frontend application will have a upload form for normal users and admin dashboard for the admins for all administration tasks like approving/rejecting videos , updating video details etc.
Task Accomplished:
- Implemented the video upload form so a user can submit the details of a new video.
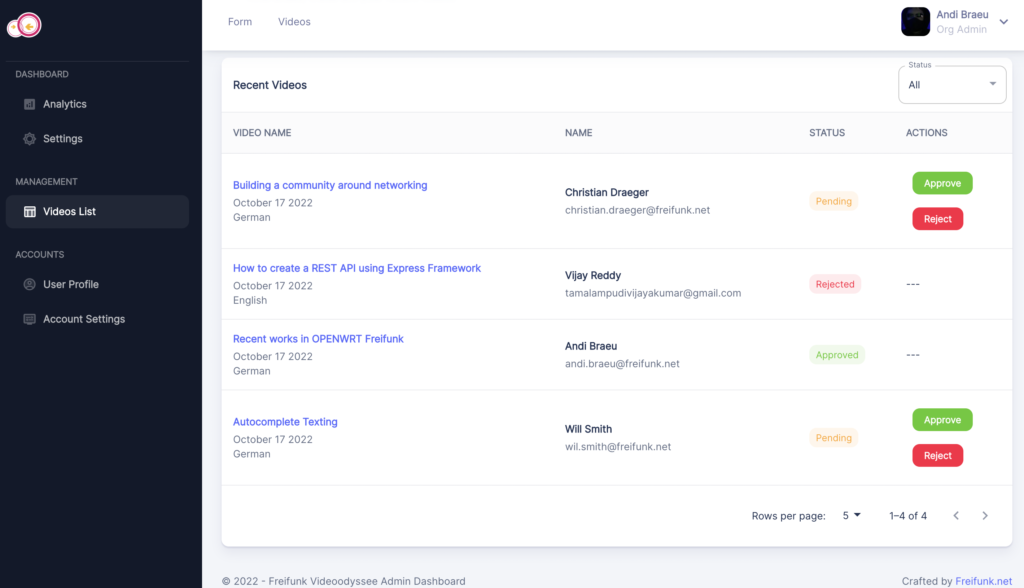
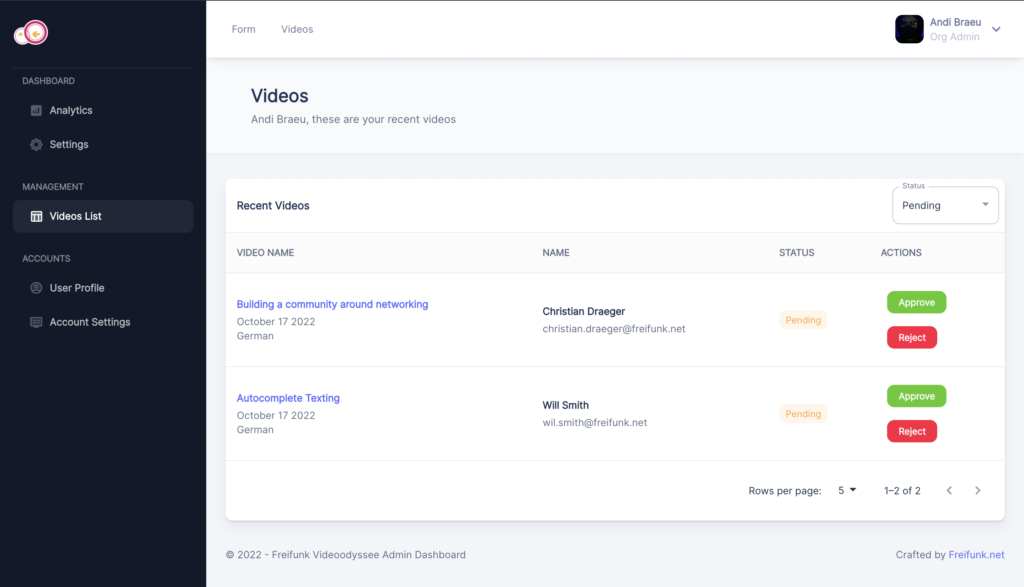
- Implemented the Videodyssee admin dashboard where admins can review the videos to accept or reject them.
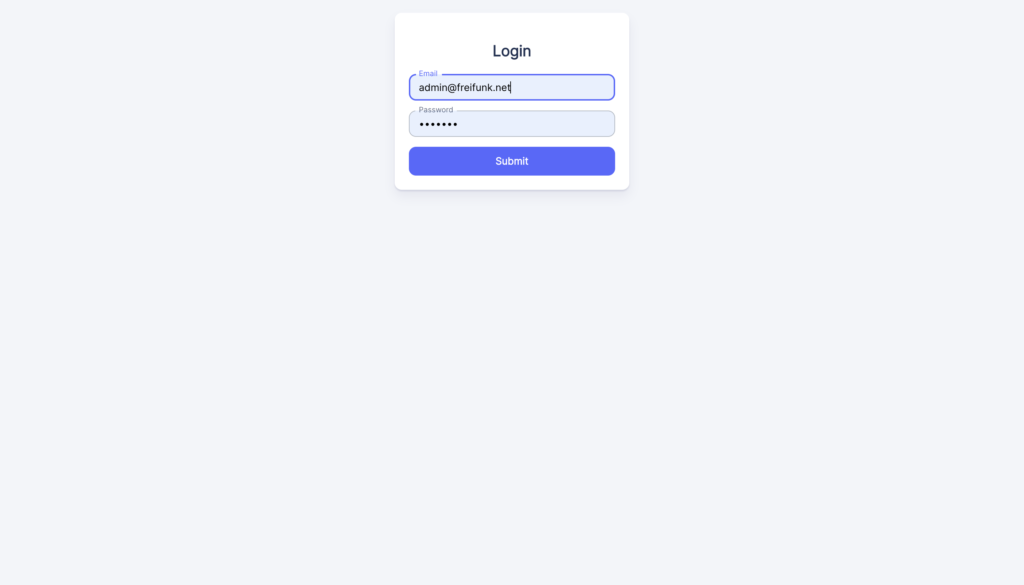
- Implemented Authentication so that only admins can access the videoodyssee admin dashboard.
Remaining Tasks:
- Implement the functionality to update the details of already published videos.
- Implement the functionality to update video details before approving a video.
- Implement the user management.
- Implement profile management.
Videoodyssee API
We used Node.js Express framework to implement the REST API which will handle the requests from the Videoodyssee frontend. We chose Express as it is quick and easy to implement a REST API using Express framework. We have used systemd as the process manager for the API server which will have some benefits like the server will restart on its own when it crashes.
Tasks Accomplished :
- Implemented a route which will take the video details from the frontend and triggers the GoCD processing pipeline.
- Automated the deployment process of REST API server using Ansible by implementing videoodyssee-api playbook.
Video review process:
- Admin logs into the Videoodyssee admin dashboard by using username and password.
- Reviews the video details and if clicks the video title he can open the video in another tab to watch it.
- If everything is fine he will approve the video.
- If some of the details are wrong he can change the details and then approves the video.
- if the admin thinks that the video is a spam video he can reject it.
Conclusion:
Finally the GSoC’22 has been pretty exciting and challenging for me .My mentor Andi Bräu really helped me a lot in the development process. I have learned a lot about open source development workflows, automation using Ansible and unit testing.
And finally , I would like to thank my mentor Andi Bräu for his incredible support and feedback.
If you got interested in my project and wanted to know more about it you can reach out to me on Linkedin.