Hi together,
now the time has come to explain the full Google Summer of Code Project. In both blog posts before I explained the work packages and structure of the Project [0][1]. In the first post I declare the three main subjects. Here is a short overview to remind of the project structure:
sub-projects,
Mainline project
and seminars.
The sub-projects are background work for community projects.
The mainline Google Summer of Code project is to develop a new firmware for routers, based on LEDE [2]. The third point are seminars for enlightment of technical aspects of the Freifunk Community.
First I would like to list up all sub-projects and their status.
The first of the sub-projects is the hoodselector. For a final explanation of this construct I would like to explain the following points to give you a good understanding of this concept. On the Nordwest Freifunk community we had one big problem. Due to the batman-adv management traffic, the network setup is not really scalable. This problem also exists on many other communities where they have thousands of mesh routers inside one single network. If there are too many routers inside of one layer 2 network the batman-adv management traffic will flood this network and make it useless.
Therefore in the Nordwest Freifunk Community we decided to develop the concept of hood-networking. This concept consists of two main components: The hoodfile [3] and the hoodselector[4]. The hoodfile is a json file containing all informations necessary for a definition of a geobased hood. One hood is defined by a geostationary fixed quadrants, VPN-peering- and wireless configurations. Inside a hoodfile are multiple hoods defined[5]. Following an example of a definition of a hood:
{
“name”: “rastede”,
“bssid”: “02:00:0A:12:A0:00”,
“defaulthood”: false,
“servers”: [
{
“host”: “ras01.sn.ffnw.de”,
“port”: “10000”,
“publickey”: “ca1b5487ffc20a1f90e0ac14e835d84ab9e52612b5ca62e073d0a13dad98775e”
}
],
“boxes”: [
[
[
53.22,
8.09
],
[
53.36,
8.32
]
]
]
},
A hood has the following definition:
– name
The name describes the region depending on its geo coordinates. For example, if you create a hood over the city Oldenburg(Oldb) (Germany), a good name could be Oldenburg or ol as short. Every name has to be unique inside a hoodfile. Redundant names are not allowed!
– bssid
The bssid will be set for the adhoc wireless interface. This is the main part of splitting the layer 2 network. Inside the bssid there is the IPv4 sub-network encoded which is in use inside the hood. In the above json part the following IPv4 sub-network is encoded “10.18.160.0/21” dec to bin => “0000’1010 0001’0010 1010’0000 0000’0000” bin to hex => 0x0A 0x12 0xA0 0x00 hex to mac => 02:00:0A:12:A0:00. Therefore the bssid should also be unique.
– defaulthood
The defaulthood boolean is only true on the default hood. The default hood doesn’t have coordinates and is the inverted form of all other hoods with geo coordinates.
– servers
Contains an array of VPN connection informations. These informations are:
VPN server address (host)
VPN port
VPN crypto key
One VPN server should be used for one hood only! If two hoods have the same VPN server, batman-adv will loop them over VPN.
– boxes
This 3 dimensional array describes the geographical size of the hood. The surface is rectangular. You just need two points per box to reconstruct it. Here is an example:
53.22,
8.09 #____________
| |
| |
| |
|____________|
# 53.36,
8.32
Each hood can have any number of rectangles inside the boxes array.
To make your life a little easier you can use the hoodgen[6] and source[7] to write your json with the required informations. This is a simple web visualization tool to plan hoods and generate the right json format for the hoodfile. This tool has been written by Eike Baran. Big Thanks to him for this helpful tool!
Now to the hoodselector.
It is a software that creates decentralized, semi automated ISO OSI layer 2 network segmentation for batman-adv layer 2 routing networks. This program reads the geobased sub-networks called hoods from the above mentioned hoodfile. The decision of choosing the right hood is made on following points: first, the hoodselector checks, if the router has a VPN connection. If it has, the hoodselector then checks, if a static geoposition was set on the router. If not, it tries to get a position using wireless based localization with the so called geolocator. The geolocator [8][9][10] is a software which makes it possible to receive a position based on wireless networks “seen” around. These informations will be sent to the openwifi map project [11]. Knowing the position of the router the hoodselector can find the right hood, because each hood is defined with geocoordinates. If the Router doesn’t have a VPN connection e.g. as a mesh only router, the hoodselector triggers a WIFI scan and searches for neighboured mesh routers in other hoods. If there is an other router with a different BSSID but with the same mesh SSID, the router chooses it’s hood based on the neighboured BSSID. I got much positive feedback from many other Freifunk Communities. Someone even created a integration request issue for gluon [12]. Gluon is a framework based on openWRT[13] and is very popular in the Freifunk community [14]. Before I will send this as a patch to gluon there remains one last urgent issue [15]. The current hoodselector is not able to handle mesh on LAN or WAN connections. So there is still a potential point of failure. Because persons who are not familiar enough with the hood-networking concept can accidentally interconnect hoods over the mesh on cable functions. I plan to fix this problem up to mid of september. When this issue is closed I would like sending patches for integration to gluon. Other issues can be found here[16].
On the Nordwest Freifunk community we currently have 10 active hoods including a default hood. That is a special hood where all routers will connect to, if they are not able to choose a hood, including also routers there out of ranges from other real hoods. After the last 3 months we can safely say that the setup works. Commits can be found here[17] All currently active hoods can be see here in this picture.
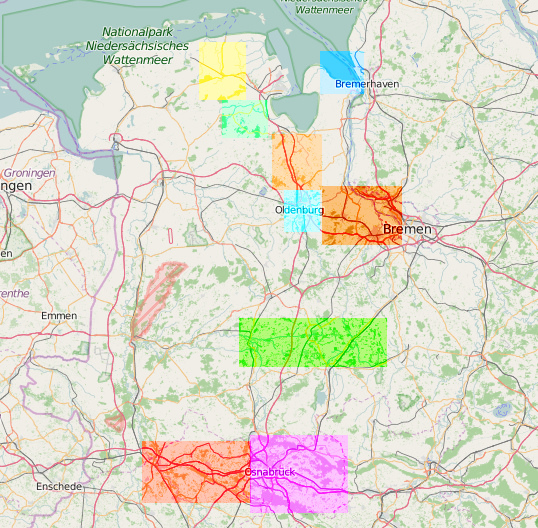
As next I would like to tell you about the second sub-project as a prework for the mainline project. In that part I work on a proper workaround with the continuous-integration (CI) system of Gitlab[18]. As I explained in the midterm evaluation, on our Nordwest community we started automatically building of nightly testing firmware images for our community firmware. The CI works now with a dynamical multiple core build processes and auto generated architecture targets out of source. At the moment it is not possible for Gitlab to handle high verbose inside the web-engine while the build process. I discussed the problem with the gitlab team and open an issue [19]. The CI builder is very helpful for the developing process of the monitoring drone. Here you can see the result for the local community image[20] and for the monitoring-drone [21].
Mainline Project.
The mainline project was to create a new firmware for monitoring and quality assurance of open wireless networks. So I started reading of informatins about openWRT [13] and LEDE [2]. I decided to use LEDE as base system. I know there still no release to use this as a defined base structure (we are all looking forward to this moment) but since july 2016 I am on the developer list and the way where LEDE is growing looks good. Next I looked for a build management script. First I thought about using make and Makefiles but this was not my favourite, so I decided to use the buildscript from the Franken Freifunk community as base, which is written in bash. Now I’ll explain the structure how to work with and use it. The following directories and files are important for basic work:
buildscript ← File
BSP ← Dir
Community ← Dir
build_patches ← Dir
modules ← File
The buildscript is mainly a bash script for a humanly working with this buildroot. In other words it is an abstraction from the LEDE build ENV.
Inside the BSP directory are all necessary architecture specific informations.
BSP means Board-Support-Package. Also inside this directory are default informations like the shell banner system configs and so on.
The community directory includes community specific configurations, similar like the gluon siteconf [22]. Currently there are only two config parameters inside: first the “AP SSID” to set a default SSID with witch WIFI network should the monitoring-drone connect and the second parameter, the “AP BSSID” to set a node specific BSSID in case if more than one router with the same SSID is present. Then the monitoring drone is pinned on one specific node. This config parameter will be dropped in the future because it is not really effectively if a default BSSID is set . In future I plan to configure thous parameters over an extra web interface[23].
In the build_patches directory you can put patches for LEDE or if you what you can also put patches for each package repository. Here is a schemata:
build_patches
lede
0001-this is a patch.patch
0002-this is another one.patch
ffnw-packages
0001-this is a patch.patch
0002-this is another one.patch
The last file is called modules. Inside this file you can add external package repositories and also select specific packages out of this repositories. Following an example:
OPENWRT=(ffnw-packages
$PACKAGEURL
$PACKAGEREV)
OPENWRT_PKGS=”libwlocate lwtrace ffnw-node-info hoodselector”
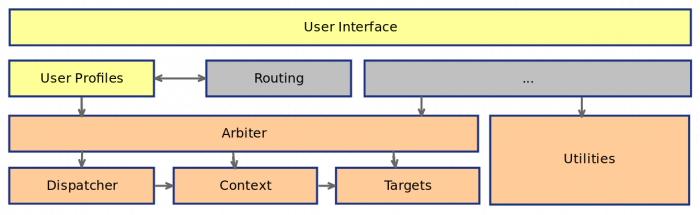
Clemens and I discussed about the API design[24] regarding the communication between the monitoring drone and the netmon core. So we met together. Here a picture:

At last point were the seminars. During the Google Summer of Code we started to gave seminars for technical aspects of Freifunk because we have not enough developers and system administrators. That is mostly a big problem in volunteer activities. On the hacking sessions we follow a simple structure:
– two lectures about Freifunk technical aspects.
– discus about the contend of the lectures
– work session on projects
On the first hacking session at the 28. may 2:00 PM we created video recordings of the two lectures, you can find them here[25]. The next hacking session were failures because of Clemens and my exams. In future there will follow other streams about tecnical aspects of Freifunk.
Last but not least, my future plans:
For the hoodselector, I plan to close up the last urgent issue[15] that I mentored in the above for the migration into gluon I also started prework on gluon for this. One part was the implementation of a sequential code minifying process at compile time [26]. Also some other issues are still open so I will continuing the work on the hoodselector[16].
For the monitoring firmware they currently is just configurable over ssh. A web interface should follow soon and also a plugin system for community specific monitoring data requests.
On the Kieler Linux information days[27] inside the Kieler Innovations- and technology center I will hold amongst others 4 presantations about Freifunk relevants themes:
Hoodselector – Network segmentation for Layer 2 routing at 11:00 (16.09.2016)[28]
Wireless-based localization (openwifi.su project) at 13:00 (16.09.2016)[29]
OpenWRT Embedded Linux distribution at 16:00 (16.09.2016)[30]
Freifunk Kiel/Nordwest (2016) – year review at 16:00 (17.09.2016)[31]
[0] http://blog.freifunk.net/2016/monitoring-and-quality-assurance-open-wifi-networks-out-client-view
[1] http://blog.freifunk.net/2016/monitoring-and-quality-assurance-open-wifi-networks-out-client-view-midterm-evaluation
[2] https://lede-project.org/
[3] https://git.nordwest.freifunk.net/ffnw-firmware/packages/blob/master/hoods/files/lib/ffnw/hoods/hoods.json
[4] https://git.nordwest.freifunk.net/ffnw-firmware/packages/blob/master/hoodselector/luasrc/hoodselector
[5] https://git.nordwest.freifunk.net/ffnw-firmware/packages/commits/master/hoods
[6] http://hood.ffnw/hoodgen.html#
[7] https://git.nordwest.freifunk.net/ffnw-server/hoodgen
[8] https://git.nordwest.freifunk.net/ffnw-firmware/packages/tree/master/libwlocate
[9] https://git.nordwest.freifunk.net/ffnw-firmware/packages/tree/master/lwtrace
[10] https://git.nordwest.freifunk.net/ffnw-firmware/packages/tree/master/ffnw-node-info
[11] http://openwifi.su/
[12] https://github.com/freifunk-gluon/gluon/issues/789
[13] https://openwrt.org/
[14] http://gluon.readthedocs.io/en/latest/
[15] https://git.nordwest.freifunk.net/ffnw-firmware/packages/issues/63
[16] https://git.nordwest.freifunk.net/ffnw-firmware/packages/issues?label_name%5B%5D=hoodselector
[17] https://git.nordwest.freifunk.net/ffnw-firmware/packages/commits/master/hoodselector
[18] https://about.gitlab.com/gitlab-ci/
[19] https://gitlab.com/gitlab-org/gitlab-ce/issues/18039
[20] https://git.nordwest.freifunk.net/ffnw-firmware/siteconf/builds
[21] https://git.nordwest.freifunk.net/ffnw-firmware/monitoring-drone/builds
[22] https://github.com/freifunk-gluon/gluon/tree/master/docs/site-example
[23] https://git.nordwest.freifunk.net/ffnw-firmware/monitoring-drone/tree/master
[24] https://git.nordwest.freifunk.net/groups/netmon-sc
[25] https://www.youtube.com/channel/UCX0nJzimLNF38pfgQIuZLEQ
[26] https://github.com/freifunk-gluon/gluon/commits/master?author=2tata
[27] http://www.kilux.de/
[28] http://www.kilux.de/index.php?seite=programm.html&untermenu=Besucher-Info#248
[29] http://www.kilux.de/index.php?seite=programm.html&untermenu=Besucher-Info#246
[30] http://www.kilux.de/index.php?seite=programm.html&untermenu=Besucher-Info#247
[31] http://www.kilux.de/index.php?seite=programm.html&untermenu=Besucher-Info#263

 ). But that should give you an idea of what is to come in the UI department.
). But that should give you an idea of what is to come in the UI department.