I’m Sandra Taskovic, an Honors Computing Science student at the University of Alberta in Canada. This summer, I’m excited to participate in a 90-hour Google Summer of Code project, where I will develop a Social Media Archive Explorer for the Freifunk community.
Project Need
Freifunk has accumulated valuable content across its past social media accounts. This project aims to harness that existing data and re-display it in a new, user-friendly static site. This Social Media Archive Explorer will give the Freifunk community greater independence and long-term control over its outreach history while staying aligned with its commitment to open-source tools.
The archive also aims to engage the community in celebrating its achievements. I’ll design a Freifunk-inspired frontend to ensure the experience is functional and reflective of the community’s spirit, further supporting its ongoing growth and outreach.
Technologies
Programming Languages: TypeScript / JavaScript
Static Site Generator (SSG): Astro
Data Source: Archived SQLite3 database of past X (formerly Twitter) posts
Data Extraction: Custom script developed to parse and extract relevant content for the site
Frontend: Additional UI libraries and design packages will be used to create a Freifunk-inspired theme and aesthetic
Plan of Action
Select the Static Site Generator – Finalize the choice of SSG—currently, Astro is the preferred option.
SSG Setup – Set up the SSG and ensure all related technologies are working. Begin early discussions around prototypes to determine which data fields need to be extracted from the database.
Develop Data Extraction Tool – Build a script to extract relevant fields from the archived SQLite3 database and normalize them into a unified schema.
Create Static Site Mockup – Generate an initial static website using the parsed and structured data.
Implement Client-Side Search – Add client-side search functionality by preprocessing and indexing data during the build process.
Test, Optimize, and Ensure Scalability – Conduct thorough testing and optimization. Ensure the site remains stable and the search remains accurate, even when additional archives are added.
Design and Implement Theming Support – Build an engaging, Freifunk-inspired frontend and implement support for customizable themes via configuration files.
Documentation and Deployment – Write comprehensive documentation and deploy the final static site.
Conclusion
I’m genuinely excited to bring this project to life during GSoC 2025. I look forward to sharing my progress and learnings throughout the summer. A heartfelt thank you to Andreas Bräu, who will be mentoring me on this journey—I’m grateful for the support and guidance ahead.
Hi everyone! I’m Mohit Kumar from Gurgaon, India. I pursued my bachelors in Electronics and Communication Engineering from Indian Institute of Information Technology, Nagpur. I’m very interested in the future of freedom tech which aligns very well with qaul and freifunk projects. Interestingly, I also had a course on Wireless Communication, and that got me hooked on the projects related to freifunk community as well.
In past I’ve contributed to a few open source projects, such as coinswap, eclair-cli, health claims exchange, etc.
About project
qaul is an internet independent wireless mesh communication app. qaul enables you to communicate P2P with people around you without any internet or communication infrastructure, using your local wifi network or via the shared wifi network of your phone. My project focuses on implementing the user authentication layer between libqual and UI, and end to end encryption.
Key features
Developing the authentication system.
Introduce session management.
Implementing End to End Encryption.
In this initial phase, I’m learning more about qaul codebase and discussing design choices for the authentication system with my mentor.
Who would gain from this project?
This would bring several benefits to community networks and various stakeholders. Users:
With improved scalability, the network grows organically without compromising the security or the performance.
Communication between node(libqaul) and UI would be secure and authenticated.
Users would have the possibility of using several identities on the same node.
A node could be a shared communication resource for all users not having the app installed but communicating via a web-interface, being connected to a central node.
Developers and Contributors: The project lays the foundation for a web interface. The authentication system and session management systems create a more extensible architecture, allowing developers to build additional features and functionalities.
Looking Ahead
I’m excited to collaborate with the qaul team and the wideeer freifunk community. Through this project, I hope to grow as a developer, contribute meaningful code, and support decentralized communication efforts.
I’m very grateful to Mathjud for his mentorship, which made my initial hurdles(of exploring new project) a bit smooth. And a huge thanks to the Andibraeu, and the whole community.
Hello everyone! I’m Agustin Trachta, a Computer Engeneering student at National University of Cordoba (Argentina), and I’m thrilled to be participating in Google Summer of Code 2025 with Freifunk, working onLibreMesh!
This summer, I’ll be focusing on simplifying and modernizing LibreMesh by:
Migrating legacy components to OpenWrt-native solutions, such as replacing custom scripts like deferrable-reboot with watchcat, and moving DHCP handling from dnsmasq to odhcpd.
Removing unnecessary complexity, like VLANs on Babel interfaces, which have caused compatibility and MTU issues.
Creating a layer-2-only variant of LibreMesh tailored for lightweight community deployments, based on BATMAN-adv.
My goal is to help make LibreMesh leaner and more accessible to new users, especially communities that rely on low-resource hardware and need plug-and-play reliability. Many of these networks operate in rural or underserved areas where internet access is limited, budgets are tight, and technical expertise is scarce. In such environments, every kilobyte of firmware matters.
By replacing legacy components with OpenWrt-native solutions, we reduce the need for LibreMesh to maintain parallel tools, making the codebase easier to understand and integrate with upstream developments. Additionally, offering a layer-2-only firmware variant allows communities to deploy simpler, lightweight networks that require minimal configuration, consume fewer resources, and are easier to debug.
What I’ll Be Working On
The first task involves replacing LibreMesh’s custom deferrable-reboot script with watchcat, a integrated OpenWrt package. The original script was created to schdeule periodic reboots in order to recover from possible instability after long uptimes, great idea but it’s already implemented in a more robust way, allowing also to trigger network interface restart based on ping failures. Migrating to watchcat ensures better integration with OpenWrt’s LuCI interface.
The second task focuses on improving DHCP handling by transitioning from dnsmasq to odhcpd. While dnsmasq is widely used and remains excelent for DNS forwarding, it’s not ideal for handling modern DHCPv6 configurations and dynamic lease sharing. This migration has been requested for years by the community, and I will work hard on making this a reality!
The third task is about removing VLAN from Babel routing interfaces. LibreMesh always used VLANs to isolate Layer 3 traffic from BATMAN-adv’s Layer 2 mesh, but it introduced issues like lower MTUs, hardware incompatibilities and added configuration burden. My work will include applying and testing relevant patches that have already been worked on, updating configurations and validating that removing VLANs does not introduce routing lops or instability.
Finally, I’ll be developing a Layer-2-only version of LibreMesh, this is other request from the community members who want a simpler and lighter firmware that doesn’t include routing extra daemons. In small mesh networks, users only need a transparent Layer 2 bridge using BATMAN-adv and gateway node doing NAT, my goal is to create a dedicated firmware profile that includes only the essential packages for a Layer-2 mesh and removes unnecessary services. This variant will help networks that value simplicity, speed, and minimal configuration, especially on older routers with tight resource constraints.
Plan of action
To ensure that each change is reliable, compatible, and valuable to the LibreMesh community, I’ll follow a staged and test-driven approach throughout the project.
I’ll begin by setting up a virtualized test environment to quickly prototype and iterate on changes. In parallel, I’ll be using at least three physical routers compatible with LibreMesh to validate the behavior of the firmware under real-world conditions.
Each task will follow a similar cycle:
Development and Integration of the change in the LibreMesh build system.
Configuration and Testing, both in isolated and multi-node environments.
Documentation and Feedback, where I’ll share results with the community, post updates, and adapt based on what users report.
I’ll be actively engaging with the LibreMesh mailing list, GitHub issues, and chat channels to keep the process transparent and collaborative.
Conclusion
I’m very excited to be working on this project as part of the GSoC 2025. I’m looking forward to collaborating, learning, testing, and sharing throughout the summer!
Also I would like to thank my mentor, Javier Jorge, who will be guiding and teaching me a lot about open source projects and local networks.
Hello everyone! I’m Victor Spehar, a Master’s student from Paris studying operating systems and distributed systems, and this is my first blog post for Freifunk!
This summer, I will be participating in Google Summer of Code 2025 for the Freifunk sister organization, LibreMesh, under the mentorship of Javier Jorge, where I’ll be working on adding Wi-Fi support to QEMU simulations in LibreMesh.
In simple terms, the goal of this project is to have:
A fully virtualized Wi-Fi router running LibreMesh firmware
The ability to “bridge” these virtual machines through their Wi-Fi interface in order to create a mesh network
A more realistic testing pipeline – as far as virtualization goes – to catch regressions earlier and improve overall reliability of LibreMesh
What Is LibreMesh?
LibreMesh is a modular framework for creating OpenWrt-based firmware for wireless mesh nodes. It aims to enable non-expert users to set up mesh networks and manage them through a simple web interface.
Setting up LibreMesh goes like this : First, find your router, then follow the installation procedure, and voilà – you have a node that is set up and ready to mesh!
Wi-Fi mesh networks provide an easy, cost-effective way to distribute Internet access in large buildings or public places, but they can also effectively be used to bridge 60+ families together. In LibreMesh, it’s simple to host services on each node because every router has its own hostname, making it easily reachable from anywhere in the mesh.
Testing in LibreMesh
Testing is an essential part of any software project: it ensures that new changes don’t introduce regressions and that features work as intended across different environments.
Currently, LibreMesh firmware testing is done in multiple ways:
Unit Tests of the lime-packages
Individual lime-packages are covered by unit tests. A Docker container emulates the OpenWrt userland, but all system-level configuration – which normally runs through UCI – are mocked or stubbed out.
Pros:
Easy to run, providing quick insight into which package might be broken
Generates coverage metrics
Cons:
Not so easily expandable : mocks up need to be set up
Does not emulate a real-world environment, and the distributed nature of LibreMesh
Abstracts the entire kernel, system configuration cannot be tested that way
Testing on Real Hardware
LibreMesh is tested on real physical routers, but this process is:
Hardware intensive: Multiple routers required and possibly different clients (laptops, smartphones, etc.) to connect to the mesh
Time intensive: Each router needs to be flashed with the correct firmware version, all hardware must be set up, configured, and every steps should be documented manually
Additionally, there are currently no automated tests or a documented, repeatable procedure for hardware testing. This kind of testing is not easily reproducible, lacks observability (the bane of a distributed system – and it’s even worse when you are transmitting data over thin air!) and requires manual effort and lots of steps, but it remains essential to catch hardware-specific regressions.
QEMU-Based Testing
At the moment, LibreMesh provides scripts to spin up multiple virtual machine instances and connect them via an Ethernet bridge. Unfortunately, this setup does not cover LibreMesh’s core feature set: Wi-Fi meshes. Moreover, although these virtual machines provide helpful information to developers, no automated tests exist for this environment in LibreMesh, meaning no repeatability.
Since some communities rely on LibreMesh firmware for Internet access, an undetected regression in a new release could cut off users from essential services. Ensuring robust and reproducible testing during development is therefore essential.
Further integrating QEMU-based testing into LibreMesh will enable more realistic scenarios: no more mocking or stubbing for general system configuration testing, and the ability to perform Wi-Fi tests in a virtualized environment by leveraging the Linux mac80211_hwsim kernel module – already widely used by kernel developers for testing Wi-Fi.
A beneficial side effect: Once a test is set up for a QEMU virtual machine, it now can also run on real hardware ! The tests meant for a QEMU virtual machine should run the same on real hardware, meaning from two birds, one stone!
Plan of Action
The Linux mac80211_hwsim kernel module provides support for virtual WLAN devices – allowing us to access, configure, and observe a virtual Wi-Fi interface. It allows the users to set up, monitor and test all kind of configuration for Wi-Fi – no limitation in software compared to hardware, and it’s also not bound to legislation since all of this is virtual, and no radiowave being emitted. A detailed article describing its use can be found here
The idea would be to create a LibreMesh virtual machine with full Wi-Fi support that could speak to similar virtual machines through the Wi-Fi stack, effectively creating a Wi-Fi mesh network, while also being truly observable, tunable, and testable. This will give us complete control over the testing environment: different topologies, latency scenarios, even roaming tests that would be difficult or impossible to recreate in real life without a large real life setup.
To achieve this, I will have to :
Include the mac80211_hwsim module in a LibreMesh QEMU image and verify that the VM boots with virtual radios
Bridge VMs through their virtual Wi-Fi interfaces so guest radios can communicate directly via Wi-Fi frames
Develop a set of scripts using RPCd interfaces for network diagnostics (e.g., checking link quality, peer discovery)
Implement automated tests for different mesh scenarios (e.g., single-link failures, packet loss, variable TX power, multi-hop reachability, routing effectiveness)
Integrate these new tests into LibreMesh’s existing testing framework
My project will enhance LibreMesh’s QEMU testing environment, improving development efficiency and deployment reliability. It won’t replace hardware testing but will catch bugs earlier in development with a faster, more robust testing pipeline and a controlled and repeatable environment.
Throughout my project, I will communicate with the LibreMesh community, sharing technical details about Wi-Fi integration in a virtualized context and providing documentation for setting up and testing LibreMesh with these new features.
Google Summer of Code: A Fantastic Opportunity!
I would like to thank everyone who made this possible. I’m truly grateful to GSoC, Freifunk, LibreMesh, and my mentor, Javier Jorge. This is my first step as an active open-source contributor and the beginning of a long, exciting journey where I’ll learn a lot!
For any suggestions or comments on my project, you can find me on the LibreMesh mailing list or the Matrix chatroom: libremesh-dev:matrix.guifi.net
Hi everyone! I’m Raul Shahi, a Master’s student in Computer Engineering for IoT Systems at Nordhausen University of Applied Sciences, Germany. I’ve been working as a Research Assistant at my university, where I’ve been developing and experimenting with tools for Wi-Fi resource control.
I was also a part of GSoC 2024, where I worked on Throughput-based Dynamic WiFi Power Control for Real Networks. Please feel free to check this blog for the project.
For GSoC 2025, I will work on building a Deep Q-Learning (DQN)-based Wi-Fi Rate Adaptation algorithm for IEEE 802.11ac networks. This project leverages machine learning techniques to address the limitations of traditional rate adaptation algorithms in dynamic wireless environments. In this blog post, I’ll walk you through the motivation, approach, and expected outcomes of the project.
Motivation
Rate Adaptation(RA) in Wi-Fi networks refers to the selection of the optimal Modulation and Coding Scheme (MCS) to maximize data throughput in the presence of varying channel conditions. As wireless links experience fluctuations due to interference, mobility, and environmental factors, a robust RA mechanism is crucial for achieving high performance. RA is a MAC-layer task that must respond rapidly and intelligently to the dynamic nature of wireless channels. The complexity of this task continues to grow with the expansion of the MCS index space, advancements in Wi-Fi standards, and increasingly heterogeneous network topologies.
Several RA algorithms have been developed to address this challenge, with Minstrel-HT being the default RA algorithm in the Linux kernel. While Minstrel-HT performs well in relatively stable conditions, its responsiveness and decision quality tend to degrade in rapidly changing environments, often resulting in sub-optimal throughput and increased latency. Study such as MAC-Layer Rate Control for 802.11 Networks: A Survery [2] provides comprehensive overviews of these limitations.
Recent research has explored the application of Deep Reinforcement Learning (DRL) to Rate Adaptation (RA), showing potential performance improvements over traditional heuristic-based methods by learning RA policies directly from network statistics such as Signal-to-Noise Ratio (SNR), throughput, or ACK failures [3, 4]. However, most of these SOTA approaches are evaluated solely in simulated environments (e.g., ns-3 or MATLAB), lack validation on commercial off-the-shelf (COTS) hardware, and often consider outdated standards like IEEE 802.11n. Additionally, they usually operate on a reduced set of MCS indices or simplified network models, which limits their applicability to modern Wi-Fi deployments with complex topologies and diverse traffic patterns.
Moreover, implementing DRL in practical systems presents inherent challenges: DRL agents typically require substantial computational resources and time for training, making real-time learning and deployment on embedded devices difficult. These issues hinder the direct transfer of DRL-based RA algorithms from simulation to real-world applications.
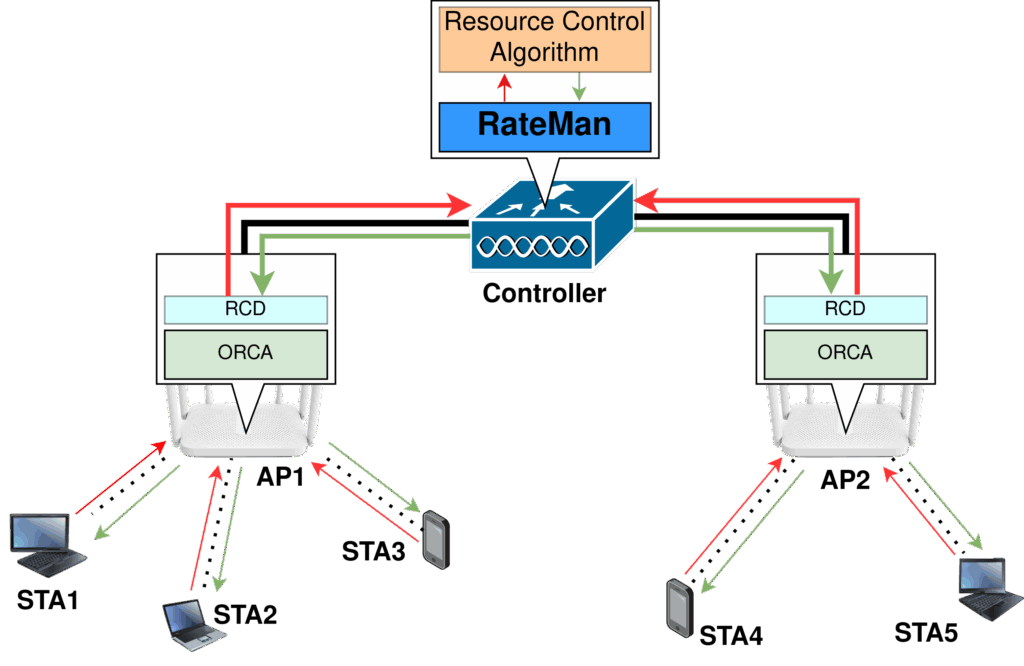
This project aims to bridge this gap by leveraging the ORCA API and RateMan framework to deploy and evaluate a DRL-based RA solution on real IEEE 802.11ac hardware, with minimal overhead and full observability into transmission statistics.
To overcome the lack of practical platforms for evaluating advanced RA algorithms, this project builds upon ORCA[1], a kernel-user space API that exposes low-level transmission statistics and allows runtime control over Wi-Fi parameters such as MCS, bandwidth, and spatial streams.
On top of ORCA, we utilize RateMan[1], a Python-based interface that simplifies per-STA rate adaptation and integrates cleanly with real-time experimental setups across multiple access points (APs). This setup offers a testbed that is both flexible and extensible, making it well-suited for developing and evaluating DRL-based RA algorithms.
Fig 1. Overview of the architecture of the user-space resource control using RateMan via ORCA[1]
This setup abstracts away kernel-level complexities, allowing developers to focus on high-level algorithm design for rate adaptation. By integrating Deep Reinforcement Learning (DRL) into this user-space framework, we can overcome the limitations of prior work, such as reliance on simulation tools, limited rate sets, or outdated standards and evaluate learning-based approaches directly on commercial off-the-shelf (COTS) Wi-Fi hardware. This bridges the gap between theoretical advancements and practical deployment, enabling reproducible and scalable experimentation in real environments.
Methodology
A Deep Q-Network (DQN) is a reinforcement learning (RL) algorithm that uses deep learning to estimate the Q-function, which represents the cumulative reward of taking an action in a given state.
Fig 2. Illustration of state, action, and reward sequence in the interactions between the agent and environment within the reinforcement learning algorithm [5]
We’ll use the ORCA API and Rateman as our experimental framework. Here’s a high-level overview of our approach:
DQN Agent Design: The agent observes channel statistics (e.g. throughput, retries, SNR) and learns to select optimal data rates.
Environment Feedback: The environment will be represented through Rateman, which interfaces with ORCA to provide real-time feedback in the form of Transmit Status (txs) events from OpenWrt-based nodes. These txs events encapsulate per-frame transmission statistics such as retry count, transmission rate (MCS), and success/failure outcomes. This detailed low-level feedback serves as the observable state for our learning agent, enabling fine-grained adaptation and evaluation of RA policies on real hardware.
Reward Function: We’ll design a reward function based on achieved throughput and transmission efficiency.
Learning: The agent updates its decision policy based on the rewards received, continuously improving its ability to choose optimal actions.
Training Strategy: We’ll apply experience replay, epsion-greedy exploration, and target network updates to stabilize training.
Evaluation: Compare performance against baseline algorithms like MInstrel-HT in both stable and mobile scenarios.
Setup
For the experimentation and evaluation of the DQN-based rate adaptation algorithm, I have access to two primary test environments:
Local OpenWrt Setup
A pair of OpenWrt-based nodes is configured, one as an Access Point (AP) and the other as a Station(STA). This setup allows for short-range, controlled experiments where the data transmission between the AP and STA can be directly observed and influenced in real-time. The system logs transmission statistics such as throughput, retry rates, and modulation rates, which are essential inputs for the learning algorithm.
The basic setup is ideal for testing initial versions of the DQN agent, debugging learning behavior, and validating the integration with the Rateman interface.
Fig 3. Local Desk Setup
Remote Shielding Box Environment
Additionally, a remote RF shielding box setup is available, which offers an advanced testing environment. The shielding box can emulate various wireless channel conditions by introducing configurable attenuation, effectively emulating mobility, interference, or range variations. This is particularly valuable for testing how well the DQN agent adapts to dynamic network environments.
Together, these setups provide a well-rounded experimentation environment. The local OpenWrt pair allows for fast prototyping, while the shielding box supports in-depth analysis under variable channel conditions. This ensures the project has ample experimental infrastructure to develop, test, and fine-tune the proposed Learning-based rate adaptation (RA)l algorithm.
Deliverables of The Project
The main outcomes of this GSoC project are :
A modular, well-documented DQN-based Wi-Fi RA agent integrated into Rateman.
A training and evaluation pipeline for testing the algorithm on real hardware using ORCA.
Performance analysis comparing our method with standard algorithms in dynamic and static environments.
A comprehensive technical report and user guide to help others replicate or extend this work.
What has been done until now?
So far, the initial groundwork for the project has been laid out, with the following accomplishments:
Explored the fundamentals of Deep Q-Learning (DQN) by implementing and experimenting with standard reinforcement learning environments such as FrozenLake and CartPole. These helped build an intuitive understanding of how Q-learning and neural networks interact in dynamic decision-making problems.
Familiarized with the ORCA API and RateMan interface
Successfully set up the experimental testbed with a pair of OpenWrt nodes configured in AP-STA mode. This local setup has been validated for basic connectivity and is ready for integration and testing of learning-based algorithms.
Studied the performance and limitations of existing ML-based rate adaptation (RA) papers to refine scope.
While the concrete architecture for integrating the DQN agent with real-world transmission feedback is still under development, the foundational components are in place. The next phase will focus on defining a robust training pipeline using txs statistics and determining how to feed real-time feedback into the learning loop.
What’s Next?
Implement the DQN agent and environment class using PyTorch.
Integrate the agent with Rateman to observe real-time transmission feedback.
Begin training and hyperparameter tuning on experimental data.
Evaluate performance and iterate over model improvements.
Conclusion
I’m incredibly excited to begin this project as part of GSoC 2025! By merging Reinforcement Learning with real-world Wi-Fi experimentation, this project aims to push the boundaries of rate adaptation in wireless networks. I hope this work contributes to more intelligent, efficient, and adaptable wireless systems, and I am looking forward to sharing updates as we move forward.
Feel free to reach out if you’re interested in the project or have any questions.
References
1. Pawar, S. P., Thapa, P. D., Jelonek, J., Le, M., Kappen, A., Hainke, N., Huehn, T., Schulz-Zander, J., Wissing, H., & Fietkau, F.
Open-source Resource Control API for real IEEE 802.11 Networks.
2. Yin, W., Hu, P., Indulska, J., & Portmann, M. (2020).
MAC-layer rate control for 802.11 networks: A survey. Wireless Networks
3. Queirós, R., Almeida, E. N., Fontes, H., Ruela, J., & Campos, R. (2021).
Wi-Fi Rate Adaptation using a Simple Deep Reinforcement Learning Approach. IEEE Access.
4. Karmakar, R., Chattopadhyay, S., & Chakraborty, S. (2022).
SmartLA: Reinforcement Learning-based Link Adaptation for High Throughput Wireless Access Networks. Computer Networks.
We’re excited to announce that our umbrella organization — representing OpenWrt, LibreMesh, qaul.net, and freifunk — is once again participating in Google Summer of Code (GSoC) in 2025!
Wireless community networks empower people to build and maintain their own infrastructure, with a focus on openness, resilience, and decentralization. This year, five contributors are working on impactful projects that support the broader ecosystem of open and community-driven networking tools. From improving user experience and developer tooling to advancing wireless communication protocols, each project reflects the spirit of collaborative innovation.
Here’s a quick overview of the 2025 projects:
📦 Social Media Archive Explorer + Frontend Nodes
Contributor: Sandra Taskovic Mentors: Andreas Bräu, Martin Tippmann
Sandra is developing tools to archive and explore social media content relevant to wireless communities, helping preserve discussions and make decentralized knowledge more accessible.
🔧 Simplifying LibreMesh with OpenWrt-Native Solutions
Contributor: Agustin Trachta Mentors: Ilario Gelmetti, Javier Jorge
Agustin is working to simplify the LibreMesh firmware by adopting native OpenWrt tools and workflows. This reduces complexity for end users and network maintainers, making community networks easier to deploy and maintain.
🔐 qaul RPC User Authentication Layer
Contributor: claddy Mentors: MathJud, Breno
In the decentralized communication tool qaul.net, claddy is implementing a secure user authentication layer for its RPC system. This enhancement will improve access control and overall network security in peer-to-peer environments.
📶 Deep Q Network-based Rate Adaptation for IEEE 802.11ac Networks
This project aims to enhance Wi-Fi rate adaptation by integrating Deep Q-Networks (DQN) with the ORCA and RateMan frameworks. Traditional rate adaptation algorithms like Minstrel-HT struggle in dynamic wireless environments, especially in fast-changing conditions.
🖧 Adding Wi-Fi Support to QEMU Simulations in LibreMesh
Contributor: Victor Spehar Mentor: Javier Jorge
To make testing easier for developers, Victor is adding Wi-Fi support to QEMU virtual machines used in LibreMesh simulations. This enables more realistic testing environments without the need for physical hardware — a big step toward more accessible and scalable development.
We’ll be sharing updates and insights from the projects throughout the summer on blog.freifunk.net, so stay tuned!
A huge thank you to our contributors and mentors for their dedication and passion. GSoC continues to be a vital part of building and sustaining tools for free and open wireless infrastructure around the world.
If you’re curious about the projects or want to get involved in community networking, we invite you to explore more at projects.freifunk.net.
Hello! This week the my project for Google Summer of Code 2024 ends, and this blog post is a final report of everything that I have done toward its goal. (Report 1) (Report 2)
During this project, I had the opportunity to attend and organize multiple events to present LibreMesh to a new public.
In August, I was invited in an open-source radio program called “radio source”, on Radio Source. During this, I had one hour to talk about and explain LibreMesh to a huge public. Being on the wave was an incredible experience where I could explain the usefulness of mesh networking, and how LibreMesh and Pirania solve many issues encountered by a community interested in setting up this kind of network. The recording of this session (in French) is available here: https://libremesh.org/news.html#2023_09_06_libremesh_on_the_waves.
The following Saturday and Sunday, I held a workshop at the Caldarium in Brussels (https://caldarium.be/en:start), where people brought their unused routers, flashed them and we built a mesh network together. Multiple people came because they heard about it from the radio event. We spent two days flashing various routers and setting them up around as far as they could in the Caldarium’s huge space, to setup a community mesh network, which is still up and being worked on.
I also organized, recorded and uploaded a QnA session which many senior members of LibreMesh attended, on how to start development on LibreMesh. This video is useful to developers as a supplement to the “development” page on the LibreMesh website. Having the opportunity to understand the project in a deeper way, and organizing these were to me the highlight of this GSoC project. The recording of this session is available on Guifi-net/eXO’s Peertube https://media.exo.cat/w/4o9xgZ65so6d5i1vmVd35z.
To finish this blog post, I will address the main goal of GSoC. During the many hours I spent understanding more and more the codebase, I didn’t manage to write functional code, only snippets that weren’t able to be integrated in the main LibreMesh code. Many of these hurdles were documented in the half-point update I made in July. As a result, I don’t have complete code to show off as a result of this project, but this GitHub repository contains code that works as an example of structure and commands that will hopefully be useful for the future of this module, and of ideas that have been shared and thought over in the mailing list.
My presence during this project started many more discussions on the topic in the mailing list and meetings, and I hope that this subject has been broadened and explored again for another go at this implementation!
I would like to thank everyone in the LibreMesh project for your time and your patient explanations, and especially Ilario for mentoring me during it, and for your sage advice. I would also like to thank Andi Bräu for managing the Freifunk role in this project, and allowing this project to happen. A gigantic thank you to everyone who reviewed this document and code on a short notice towards the end of GSoC!
If you have any questions please reach out to me at panouillot.mael@lesoiseaux.io.
Hi everyone! Welcome back to the final blog post in this series on Throughput-based Dynamic WiFi Power Control for Real Networks. In the introductory blog, I provided an overview of our project’s goal and methodologies. In the mid-term blog, we introduced the foundational elements of the power control algorithm, integrated it with Python WiFi Manager, and evaluated its early performance.
As we reach the culmination of this journey, I will summarize the latest developments, share insights from our data analysis, and discuss the probable next steps for future advancement.
1. Goal of the Power Controller
The main objective of this power controller is to achieve power adaption for Commercial Off-The-Shelf (COTS) hardware, where we lack full access to detailed feedback information.
In any setup or system where we have an estimate of the expected throughput and a mechanism to adjust power settings, this power controller can be implemented to optimize performance. Its primary focus is on real-world scenarios, making it adaptable for various use cases where full system control is unavailable.
2. Development of Power Control Algorithm
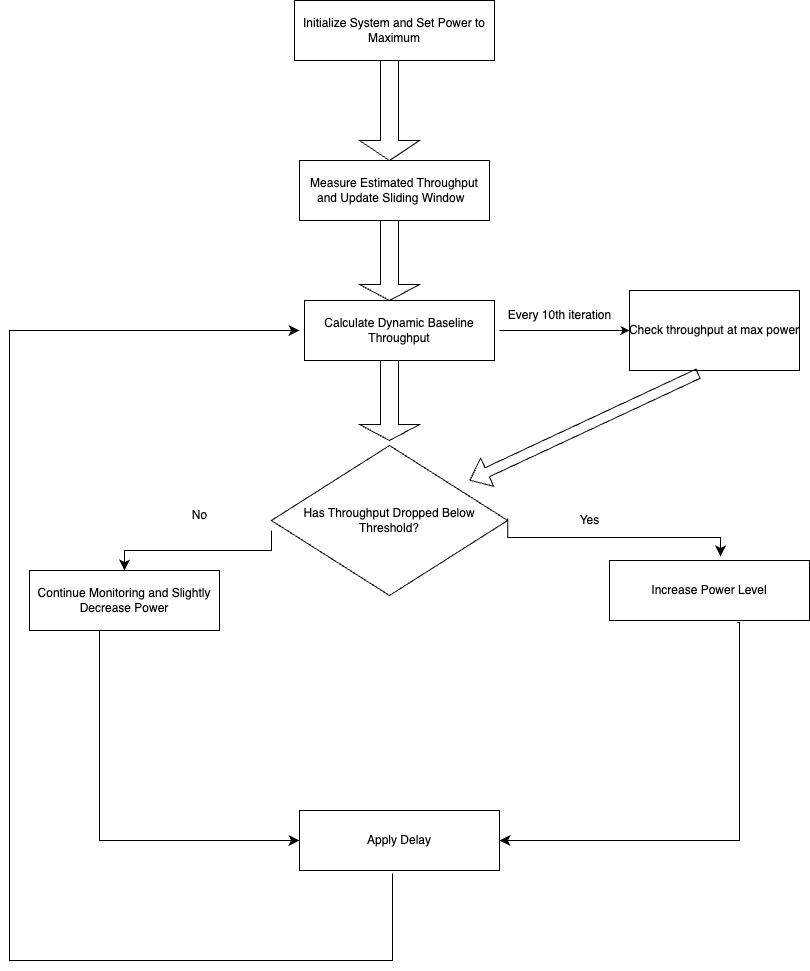
In this phase, we focused on refining the power control algorithm to dynamically adjust transmission power levels based on throughput measurements. Here’s a breakdown of the key steps and logic incorporated into the algorithm:
Supported Power Levels: Each router or station has a list of supported power levels. This list is provided by the Python-WiFi-Manager, which serves as a critical component in our algorithm.
Initial Assumption: We start with the assumption that the highest power level will yield the highest throughput. This serves as our baseline for evaluating other power settings.
Algorithm Initialization: The algorithm begins by setting the transmission power to the highest level available. We then measure the expected throughput at this power level.
Power Decrement: After measuring the expected throughput, we decrement the power level by one and take another measurement.
Throughput Comparison: We assume a certain threshold that the throughputs at lower power can be below (for example 10% of) the previous throughput. If the expected throughput at the decreased power level falls below this threshold, we revert to the higher power level. This threshold ensures that the power is only decreased if the performance impact is minimal.
Continued Decrease: If the throughput remains within an acceptable range, we continue to decrease the power level, repeating the measurement and comparison process.
Iterative Process: This process is repeated iteratively, adjusting the power level based on throughput measurements until we reach the lowest supported power level.
Periodic Maximum Power Check: Every 10th iteration, we re-evaluate the throughput at the maximum power level for a brief 60 ms. This ensures that the throughput at the current optimal power level, monitored for around 140 ms, remains within the threshold of the throughput measured at maximum power. Since we only stay at the maximum power for 60 ms, this approach minimizes the time spent at higher power levels, avoiding unnecessary power consumption.
Adjust Based on Maximum Power Check: If the throughput at the optimal power level is still within the threshold of the maximum power throughput, we continue with our usual power adjustment process, either decreasing or maintaining the lowest power level.
Fallback Strategy: If the throughput at the optimal power level falls below 90% of the throughput measured at the maximum power level (i.e., deviates by more than 10%), we restart the process using the second-highest power level to reassess and potentially find a better balance. All thresholds, including the deviation percentage and comparison intervals, are fully configurable.
This algorithm ensures a dynamic and adaptive approach to power control, optimizing network performance by continuously evaluating and adjusting based on real-time throughput data.
3. Determination of Expected Throughput
To effectively implement the power control algorithm, determining the expected throughput was crucial. Here’s how we enhanced the Python-WiFi-Manager to facilitate this:
Extension of Python-WiFi-Manager: Extension of Python-WiFi-Manager: We extended the Python-WiFi-Manager package to include functionality for estimated throughput, which is derived from the Kernel Minstrel HT rate control algorithm. Minstrel HT maintains a rate table with expected throughput based on success probabilities for each transmission rate. The estimated throughput, obtained via Netlink, is calculated using the best rate (i.e., the expected throughput of the first rate in the MRR stage) determined by Minstrel HT. The reporting of estimated throughput from both the Python-WiFi-Manager package and Netlink is consistent and identical. By integrating this information, the Python-WiFi-Manager can now monitor and utilize these throughput estimates to optimize power control decisions in real-time.
Extracting Optimal Rate: From the ‘best_rates’ lines provided by the Python-WiFi-Manager, we extracted the transmission rate that corresponds to the highest estimated throughput. This rate is a key indicator of potential performance at different power levels.
Average Throughput Measurement: Using the optimal rate identified, we then referenced the ‘stats’ lines to extract the field for average throughput. This measurement represents the expected throughput at the given transmission rate and is essential for evaluating the effectiveness of different power settings.
Integration into the Station Class: The extracted average throughput was integrated into the Station class of the Python-WiFi-Manager. We introduced a new property, ‘expected_throughput,’ to store this value. This property became a fundamental component of the power control algorithm, allowing real-time adjustments based on the estimated throughput.
By extending the Python-WiFi-Manager in this manner, we were able to leverage real-time throughput estimates effectively. This enhancement played a critical role in the development of our dynamic power control algorithm, enabling precise adjustments to optimize network performance.
4. Results from logging in the Power Controller
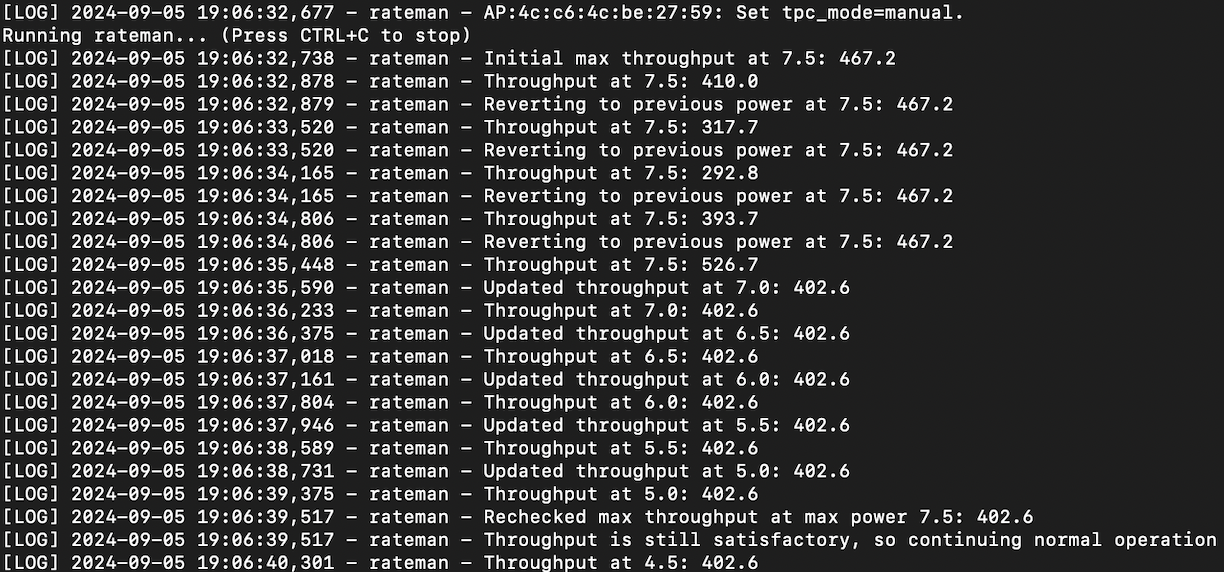
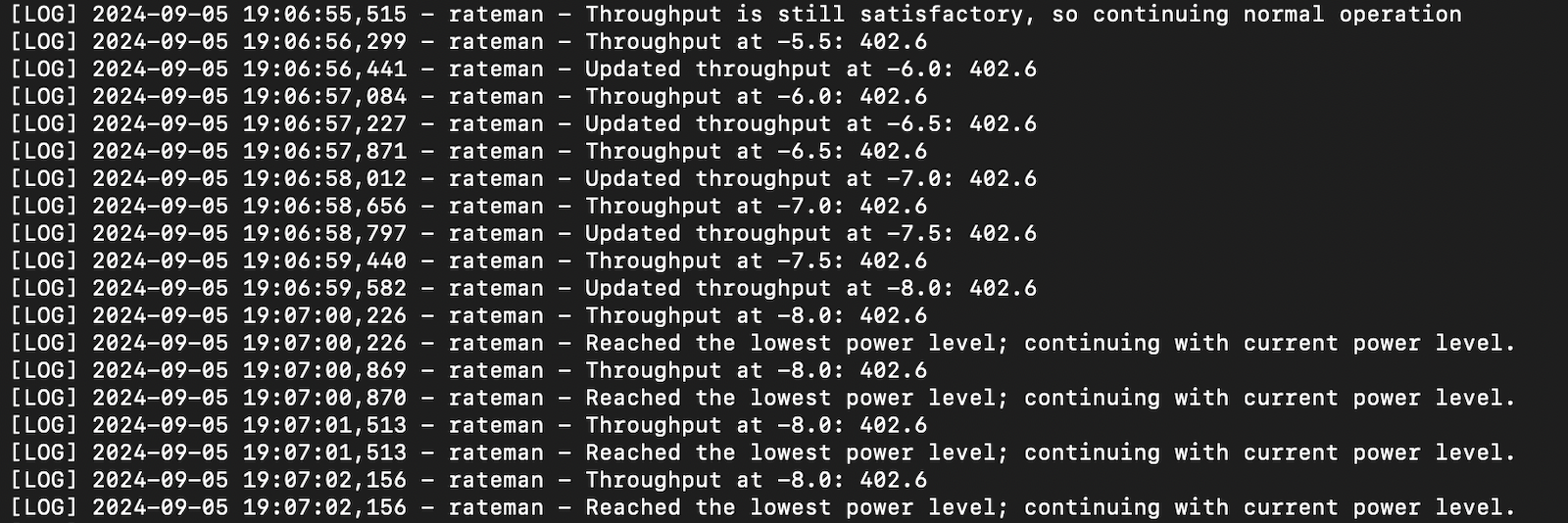
Log Overview: The power controller logs capture a range of data points, including power levels, throughput measurements, and timestamps. These logs are crucial for understanding how the algorithm adjusts power settings in response to throughput changes.
Key Data Points:
Power Level Adjustments: Logs show each instance where the power level was adjusted, including the previous and new power levels.
Throughput Measurements: Recorded throughput values at different power levels provide a basis for evaluating the effectiveness of power adjustments.
Threshold Comparisons: Instances where the throughput fell below or met the predefined thresholds are noted, offering insight into the algorithm’s decision-making process.
3. Log Sample: Here’s a snapshot of the logs
5. Experimental Setup and Configuration
a. Access Point and Station Configuration
For the experiments, two Redmi Routers with MT768 chips were used, where one acted as the access point (AP) and the other as the station (STA). Both devices utilized IEEE 802.11ac(WiFi-5) capable.
AP Configuration:
The AP was configured to operate on the 5 GHz band using channel 149 with a maximum channel width of 80 MHz (VHT80).
The 2.4 GHz band on the AP was disabled, focusing the experiment on the 5 GHz band for better throughput.
STA Configuration:
The STA was connected to the AP on the 5 GHz band, operating on the same channel (149).
This setup ensured a controlled and consistent network environment for the experiments, particularly focusing on high-speed, 5 GHz communications between the devices.
b. Traffic Generation
Traffic was generated using iperf3, a tool widely used for network performance measurement. This allowed for the creation of a consistent and controlled load on the network, essential for evaluating the performance of the power control algorithm.
c. Throughput Calculation
Throughput was calculated using packet capture (pcap) files generated during the experiments. The process involved the following steps:
Capture Data: During the experiments, network traffic was captured using tcpdump to generate pcap format to record detailed packet-level information.
Convert to CSV: The pcap files were then converted into CSV format. This conversion facilitates easier analysis and manipulation of the data for calculating throughput.
Data Analysis: The CSV files were analyzed to extract throughput metrics. This involved processing the data to determine the rate of successful data transmission between the Access Point (AP) and Station (STA).
This method allowed for precise measurement and post-experiment analysis of network performance.
d. Network Topology
In the close proximity experiments, the AP and STA were placed on the same table, approximately 2 meters apart, with no physical barriers between them. For the challenging conditions, the routers were positioned in different rooms or floors, with a distance of around 10 meters between them.
Fig. Experimental Setupin Close Proximity
6. Experimental Results
To evaluate the performance of our power control algorithm, the Experimentation Python package from SupraCoNex was utilized. This package facilitated a series of experiments conducted under various conditions to assess the algorithm’s effectiveness. Here’s a summary of the experimental approach and the results:
Experimental Setup: Multiple experiments were conducted to test the power control algorithm in both close proximity and challenging conditions, allowing us to observe its performance across varied network environments.
Data Extraction: From the experiments, we extracted key data related to rate-time, power-time, and throughput-time relationships. These data points are crucial for understanding how power adjustments impact throughput and rate over time.
Data Visualization: The extracted data was then plotted to visualize the relationships:
Ratevs. Time Plot: Shows how the transmission rate varies over time with different power levels.
Power vs. Time Plot: Illustrates the power levels used during the experiments and how they change over time.
Throughput vs. Time Plot: Displays the throughput variations over time, highlighting the performance of the algorithm in maintaining optimal throughput.
Analysis: By analyzing these plots, we were able to gain insights into how well the power control algorithm adapts to changing conditions and maintains network performance. The visualizations provided a clear picture of the algorithm’s effectiveness in real-time adjustments.
To evaluate the effectiveness of our power control algorithm, we compared it against several established methods. Here’s a brief overview of the algorithms used in the experiments:
1. Kernel Minstrel HT:
This algorithm focuses on selecting transmission rates based on observed performance metrics to optimize network performance. It employs a Multi-Rate Retry (MRR) strategy with four stages: the highest throughput rate (max_tp1), the second highest throughput rate(max_tp2), the third highest throughput rate (max_tp3), and the rate with the maximum success probability (max_prob_rate). If a rate at a given stage fails, the algorithm moves to the next stage in the sequence, ensuring continued performance optimization by using the next best available rate. This approach balances high throughput with reliable performance, adapting to varying network conditions.
2. Manual MRR Setter:
This method involves using a fixed, slower rate for all transmissions. By consistently using the slowest rate, this approach helps to understand the impact of rate adjustments and provides a reference point for evaluating dynamic control strategies. It provides a clear reference point for evaluating dynamic control strategies, helping to distinctly separate and identify the performance boundaries of different algorithms.
3. Our Power Controller:
Objective: The newly developed power control algorithm dynamically adjusts transmission power levels based on throughput measurements. It aims to optimize power settings to maintain high throughput while optimizing power and minimizing interference.
Mechanism: The algorithm starts with the highest power level, measures throughput, and progressively decreases power levels. It continuously checks throughput against predefined thresholds and adjusts power accordingly to maintain optimal performance.
A. Experiment in Close Proximity
With these algorithms set for comparison, the first set of experiments was conducted with the routers placed close to each other. The routers were positioned on the same table, approximately two meters apart with no barriers in between. This setup provided a controlled environment to accurately measure and compare the performance of each algorithm.
Observation: From the figure we can observe that if the connection is strong, the power controller can significantly reduce the power and still deliver high throughput.
B. Experiments under Challenging Conditions
Following the initial experiments with routers in close proximity, we conducted a second series of tests to evaluate the performance of the algorithms under more challenging conditions. For this phase, the routers were placed in different rooms and on different floors, approximately 10 meters apart. This setup was designed to simulate a more realistic scenario with increased distance, barriers and potential interference.
Unlike the close-proximity experiments where power levels were dynamically adjusted, in the more distant setup, the power levels did not drastically reduce at all times. Instead, the natural tendency observed was for the power to stabilize at a lower level.
The power controller effectively managed to adjust the power levels, but the adjustments were more subtle compared to the previous tests. This is indicative of the controller’s ability to adapt to the increased distance and interference by settling at a lower, but stable, power level that still maintained acceptable throughput.
7. Possible Enhancements in the Future
While the current implementation of the power controller has demonstrated promising results, there are several immediate next steps to further enhance its performance and adaptability:
Throughput Estimation Improvement: Study how well estimated throughput for optimal and highest power levels are isolated to provide better throughput estimates. This refinement could lead to more accurate power control decisions.
Complex Scenario Testing: Test the controller in more complex scenarios involving other devices operating on the same channel. This will provide insights into how the controller performs in real-world conditions with multiple network elements.
Interference Management: Conduct interference management tests with multiple access points (APs) and stations (STAs), all running the power controller. This will evaluate the system’s effectiveness in managing interference and maintaining performance in crowded environments.
In addition to these immediate enhancements, future developments could explore more advanced options such as leveraging machine learning for predictive adjustments, utilizing historical data for better adaptability, implementing time-of-day adjustments for optimized power settings, and adapting to environmental factors for improved robustness.
Conclusion
I’ve had an incredible experience being part of GSoC 2024. This opportunity has allowed me to delve into new areas, including working with Python for the first time and developing plotting scripts. I am truly grateful for the chance to contribute to this project and learn so much along the way. A big thank you to the mentors who provided invaluable support and guidance throughout the journey.
Hello! As the Google Summer of Code ends, so this project will end too. Below you find what i’ve been working on this summer. You can check Part I here and Part II here.
Recapitulating
The main goal of this project is to migrate Pirania captive’s portal rules from iptables to nftables, which is the new framework for packet processing in Linux. Pirania is intended to be a portal captive, so when a users connects to a wi-fi network they are prompted to insert a voucher or redirected to a web site of the community, for example.
A captive portal can be used by a community network as a tool to ensure the sustainability of the local network’s operation.
What was needed
When enabled, a captive portal needs to allow/block packets in order to work properly. Pirania does it by inspecting the origin MAC Address. Furthermore, IP packets need to be allowed in order to access local network services.
These rules are created by captive-portal script, which uses iptables, ebtables, ipset and uci in order to configure the rules properly. With the newer framework for packet processing only nftables and uci needs to be used since nftables understands layer 2 protocols and have ipsets functionality embedded and faster.
Also is here where lives the function pirania_authorized_macs which is responsible for returning the registered MAC addresses, that is, those that can access the Internet. This MAC can be registered via the command line by calling the captive-portal binary or via the web interface, where the user will enter the voucher.
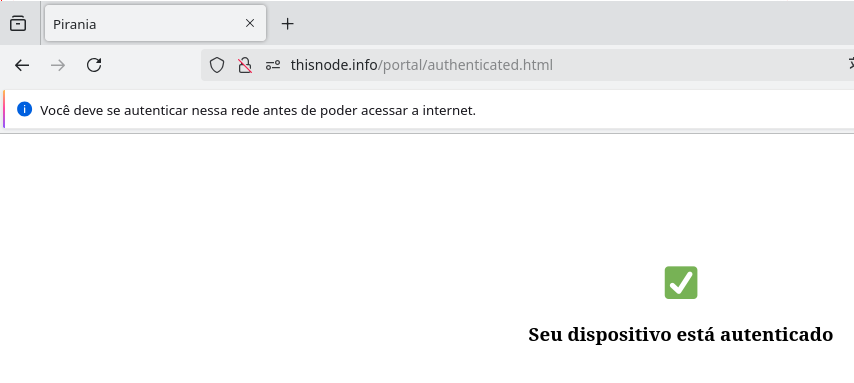
After entering a valid voucher this is the page that will appear to the user:
Steps needed:
1 – translate the script to use nftables framework.
2 – test.
For testing there is the possibility to use in a virtual environment with qemu (more info here). I spent a considerable time trying to allow internet access in a virtualized environment but i opted to use in a real hardware. The chosen hardware was a rocket m5 from the manufacturer ubiquiti. The firmware precompiled was downloaded here.
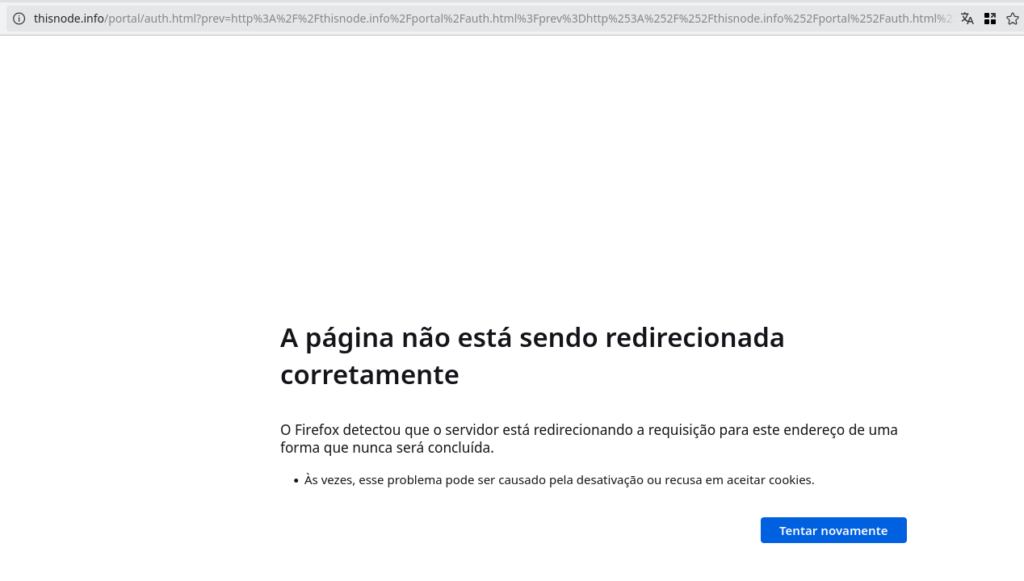
While testing the new script, i was haunted by a redirection loop. After a few modifications i was able to overcome this issue.
One of the biggest challenges was learning the new nftables framework. Fortunately, I found many examples and tutorials on the internet and I started to enjoy it. It took me a while to get used to this technology and I’m still learning. The results of my work can be found here.
The new version of LibreMesh will probably be released this year so I’ll have more work to do.
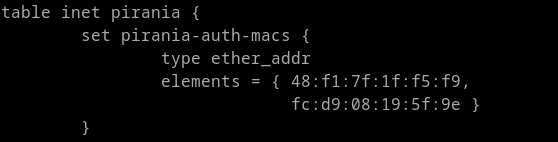
After a voucher is activated, the set pirania-auth-macs is populated, as shown above:
If a voucher is in use, its possible to list:
What i found beyond
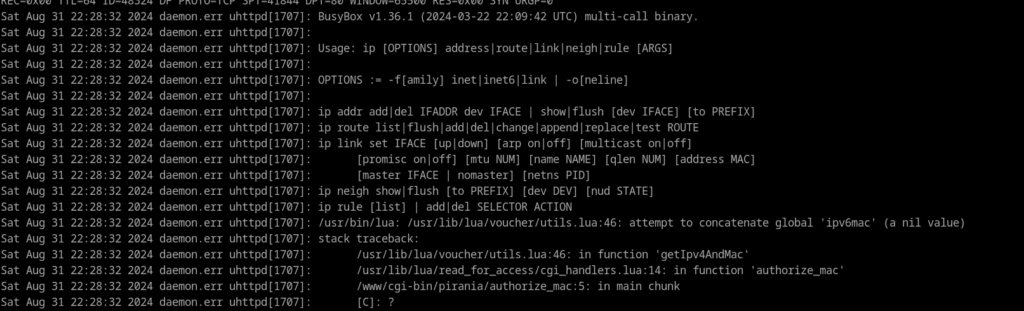
Found that some packages were missing:
Also that in utils.lua the command invocation “ip neighbor” was not working but “ip n” or “ip neigh” worked perfectly.
Next steps
Pirania and shared state are awesome packages developed by LibreMesh community. Porting these packages to OpenWRT will bring more visibility and people to contribute.
Follow the development of the new version of LibreMesh and see if there is anything that can be improved.
Conclusions
Being able to contribute to this project is something that makes me very happy. In 2015, I was looking for a relevant topic for my final project at university and I met passionate people at an event called Fumaça Data Springs, where I was able to meet some of the developers and get my hands dirty on routers with this incredible software called LibreMesh.
I would like to thank my mentors Ilario and Hiure for the opportunity to participate in GSoC 2024 and for the knowledge they shared.
I would also like to thank Andi and Freifunk for their commitment to making projects like this happen.
This concludes my project at GSoC, but if you have any questions, please feel free to contact me.
This post is the final post in the continuation of this blog series. In part 2, I discussed the theory behind Qaul BLE support for Linux and a walkthrough for creating a BLE GATT server, advertisement of services, and scanning of devices advertising qaul services. We also discussed the theory of message transfer through BLE GATT characteristics. Please refer to that blog before proceeding.
In this blog, we will explore the implementation and low-level design of the BLE support in greater depth.
Correction in the previous Blog
In the previous blog, while creating the GATT server, we defined two services:- “main_service” and “msg_service” with their respective characteristics. The issue here is, that multiple services lead to longer advertisement messages that are only supported by extended advertisements. So, for compatibility, we are using only “main_service“, which encapsulates both characteristics:- “mainChar“, and “msgChar” for normal advertisements. Rest all things are same.
Introduction
We will begin by configuring services and characteristics of the qaul device to send libqaul messages to other devices and spawn a new thread for receiving messages from all nearby devices. For byte-loss transfer, we are enclosing our data inside delimiters “$$” and then breaking it into byte arrays. On the spawned message listener, we receive messages from all nearby qaul devices and separate the messages into a map of type <qaul_id, message>. The message starts at “$$” and ends when ending “$$” is encountered. The message is then sent to libqaul for decoding.
Message receiver
The message is received by “msgChar” when some other device overwrites the value of this characteristic. While configuring msgChar, we created a msg_charcteristic_ctrl which emits an event, CharacteristicControlEvent::Write(write), io_write by characteristic. On accepting the write request into read_buffer which is then sent to ble_message_sender for further processing of bytes. Ble_message_reciever receives the byteArray in the set of 20 and maintains a map of qaul_id v/s message received till now. As soon as ending $$ is encountered, the message is sent to libqaul.
The whole above architecture works by spawning two new threads, one for receiving data from other devices and the other for manipulation of received bytes, for loss-less transfer of bytes.
Message Sender
On discovering a nearby qaul device emitting the same main_service and read_char as any qaul device, the libqaul starts to send routing messages at regular intervals for other devices to get updated on routing tables. All other public or personal messages are also transmitted similarly.
On receiving a “DirectSend” request from libqaul, ble_module adds delimiters(“$$”) to the start and end of the message. Then it breaks the message into arrays of 20 or fewer bytes each and pushes each into a queue. The Gatt client then connects to the specified server and tries to io_write the message into the value of the characteristic of the server which will eventually trigger the Write event of characteristic_ctrl.
Also, while writing data to another device, the GATT client also updates its list for last_found_time for out_of_range_checker.
Result :
We were successful in creating a reliable connection between Android 33+ and Linux devices with nearby device discovery and message transfer using ble_module.
Device discovered by Android ble_module.
Device discovered by Linux ble_module.
Messages are Successfully sent and received by both devices.
Images for BLE Message from Android to Linux
Message sent by Android.
Message received by Linux.
Images for BLE Message from Linux to Android
Message sent by Linux.
Message received by Android.
Limitations:
The above implementation works well for any Linux device with Bluetooth Adapter version >= 5.0 and Android SDK version >= 33. The absence of any of the above conditions would lead to the loss of some random bytes from the message leading to the failure of this protocol.
Conclusion
The implementation of the Bluetooth Low Energy module using Bluez is limited in extensibility and reliability, especially within the planned architecture. The instability of Linux Bluetooth can cause message loss if conditions aren’t met, indicating a need for further optimization of the BLE module and the underlying protocol to enhance robustness and reliability.
While working on the Qaul project and implementing the ble module, I learned a lot about peer-to-peer communication, routing, and Bluetooth in general.
I would like to express my sincere gratitude to my mentors, Mathias Jud and Breno, for allowing me to participate in GSoC 2024 and for their invaluable guidance throughout this project. I am also grateful to Andi and all the Freifunk members involved with GSoC for making this project possible.
This marks the end of my GSoC’2024 project, but as I mentioned earlier, there is still work to be done. If you have any questions, please feel free to reach out. I hope you found this project as rewarding and enjoyable as I did!