Hello again everybody! With GSoC 2024 coming to an end, it is time to present you my final blog post/report for my project, showing you what I have achieved during the summer.
Project Goal
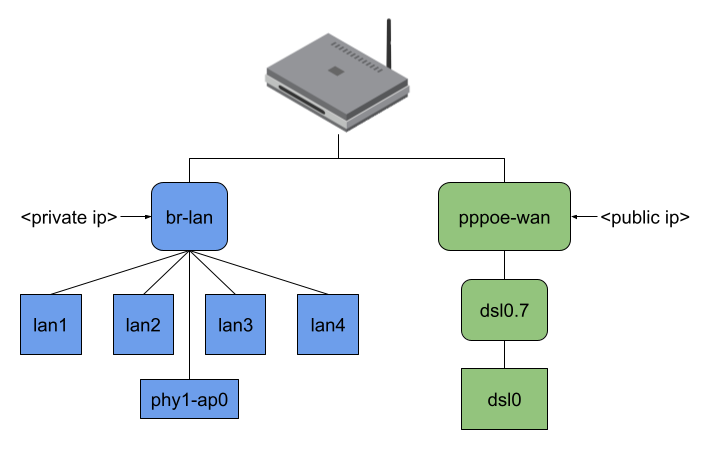
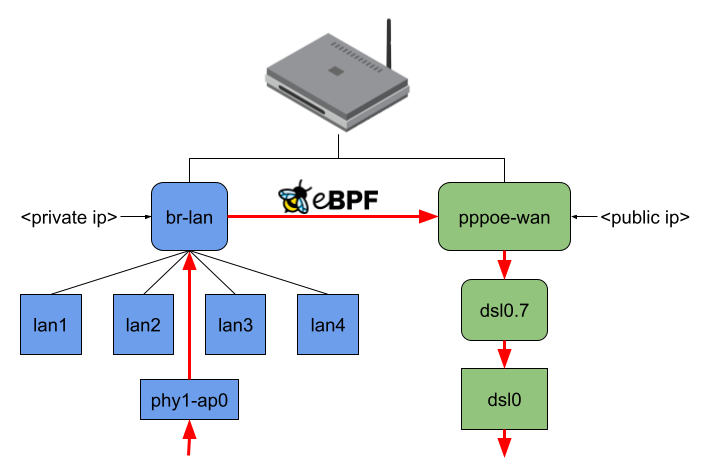
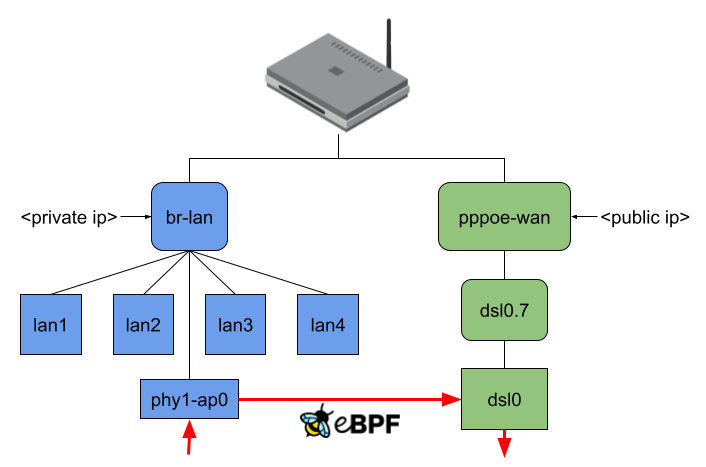
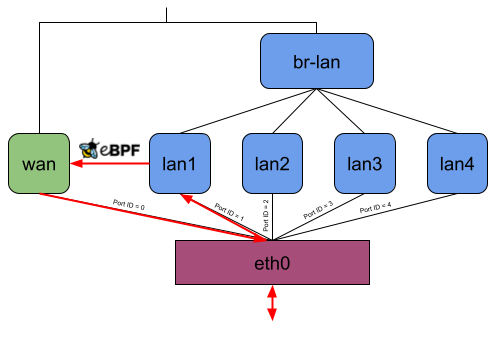
This project aims to introduce a new firewall software offloading variant to OpenWrt by intercepting an incoming data packet from the NIC as early as possible inside or even before the network stack through the eBPF XDP or TC hook. After that, the packet might be mangled (e.g., NAT) and redirected to another network interface or dropped.
The result should be that we see a performance increase, either by having a higher throughput, dropping packets faster, or lowering the overall CPU load.
More detailed descriptions of this project can be found in my first blog post here and my midterm update here.
What I did
To achieve the goals of this project, I had to design and implement three parts of the software:
- The eBPF program which intercepts, mangles, and forwards or drops incoming data packets
- A user-space program that attaches the eBPF program, reads Firewall rules, and makes routing decisions for the received packets
- An eBPF hashmap for the communication between the eBPF- and user-space program
Finally, a performance evaluation is required to compare the results of this eBPF implementation against OpenWrt’s current Firewall.
You can find my implementation, measurement scripts, and some plots in my dedicated GitHub repository here: https://github.com/tk154/GSoC2024_eBPF-Firewall
The current implementation state
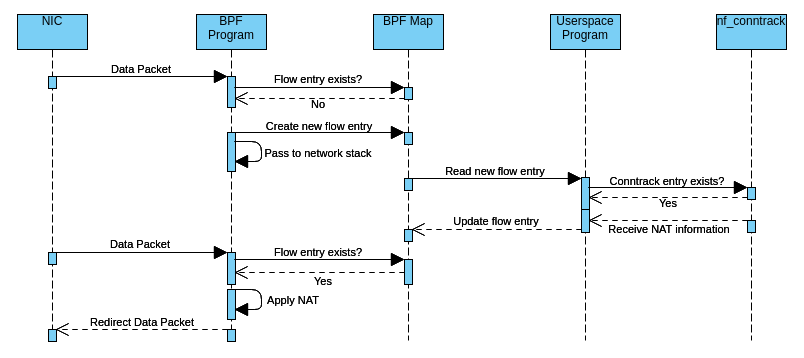
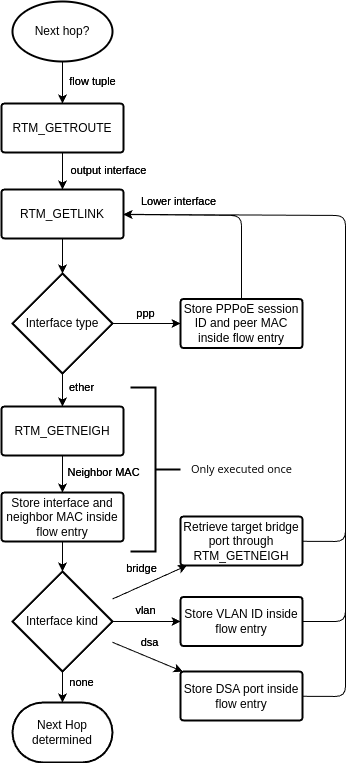
eBPF kernel-space program
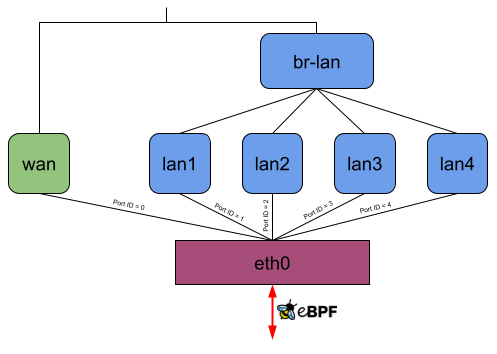
When the eBPF kernel-space program receives a packet, it parses the layer 2, 3, and 4 packet headers, and if a DSA switch receives the packet, it also parses the DSA tag. If any header is unknown in the respective layer, it passes the packet to the network stack. The following headers/DSA tags are currently supported:
| Layer 2 | Layer 3 | Layer 4 | DSA Tags |
|---|---|---|---|
| Ethernet 802.1Q VLAN PPPoE | IPv4 IPv6 | TCP UDP | mtk gswip qca |
It then checks inside the eBPF hashmap what to do with the received packet:
- If there is no entry yet for the packet/flow, it creates a new one to signal the user-space program.
- If there is an entry but the eBPF program should not redirect the packet, the packet is passed to the network stack or dropped.
- If there is an entry and the eBPF program should redirect the packet, it …
- Mangles the packet by applying NAT (if applicable) and adjusting the TTL and checksums
- Pushes the Ethernet header and possible additional L2 header onto the packet
- Sends the packet out of the designated network interface
User-space program
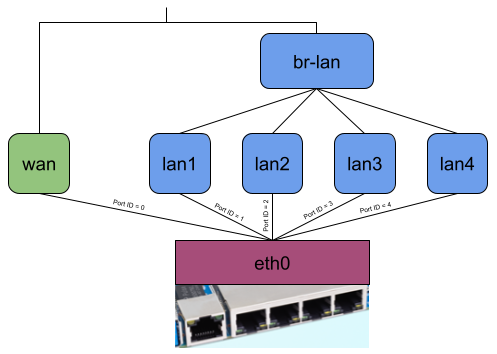
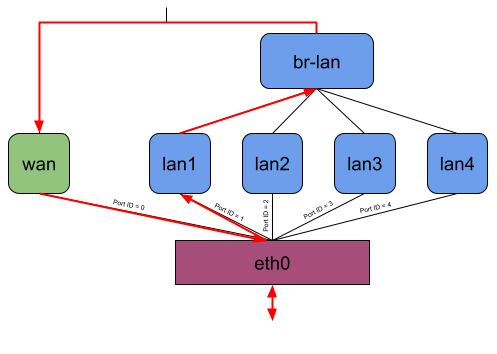
When the user starts the binary, it attaches the eBPF program to the lowest possible network interfaces on the system or to all network interfaces given by the user per command line argument.
It then loops every n seconds through the flow entries of the eBPF hashmap and checks via nf_conntrack whether a connection tracking exists for that flow.
- If so, and if the flow entry is new, it …
- Retrieves possible NAT information via nf_conntrack
- Makes the routing decision
- Checks if the eBPF program needs to push layer 2 headers
- Determines the next hop via rtnetlink
- Saves all that information inside the eBPF map to signal the eBPF program that it can take over now
- For all existing flow entries, it updates the nf_conntrack timeouts as long as an established connection tracking entry exists
- If a connection tracking entry does not exist, it checks Firewall rules via OpenWrt’s scripting language ucode if the eBPF program should drop the packet.
When a configurable flow timeout occurs, the user-space program deletes the flow entry from the eBPF map.
What is left to do
Submitting an XDP generic patch
Currently, for XDP generic, if the pre-allocated SKB does not have a packet headroom of 256 Bytes, it gets expanded, which involves copy operations consuming so many CPU cycles that the hoped-for performance gain is negated. I have already created a patch that makes the XDP generic packet headroom configurable, but I still need to submit it to upstream Linux.
Routing changes
When there is a new flow entry, the user-space program makes a routing decision and stores the result inside the eBPF map. But it could be possible that such a route changes now, e.g. because the user explicitly changed it or a network interface went down. The user-space program doesn’t react yet to routing changes, which means that the eBPF program still forwards packets to the old routing destination.
Counter updates
As soon as the eBPF program starts forwarding packets, network interface and nf_conntrack counters aren’t updated anymore. Updating the interface counters shouldn’t be a problem, but in my testing, nf_conntrack counter updates seem to get ignored from user-space.
Performance results
Similar to my first blog post, I tested the throughput performance on an AVM FRITZ!Box 7360 v2 running OpenWrt with Linux Kernel version 6.6.41, which CPU is too weak to saturate its Gigabit ports. I used iperf3 to generate IPv6 UDP traffic for 60 seconds where NAT is applied for the source and destination IPs and ports; you can find the results inside the following plot:
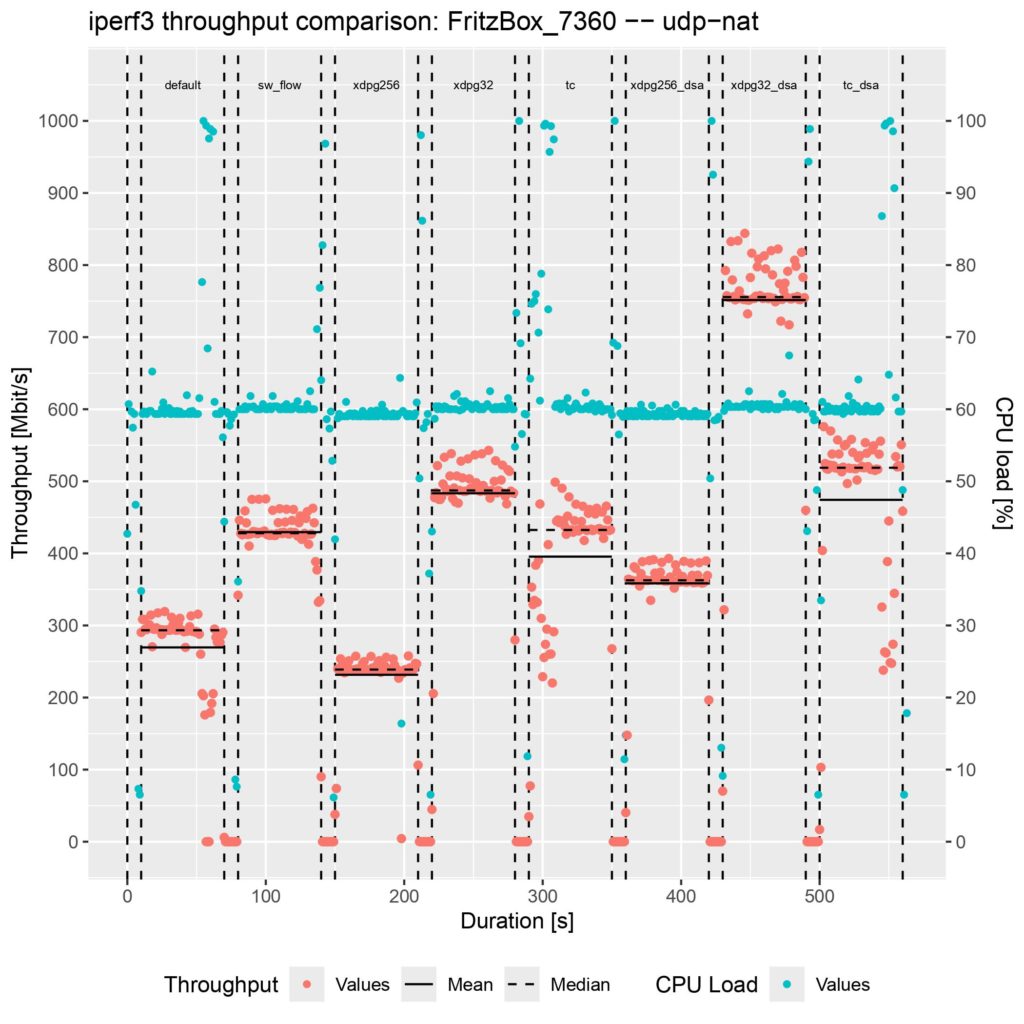
The parts are the following:
- default: OpenWrt’s Firewall running but without any offloading enabled
- sw_flow: Netfilter’s software offloading enabled (flow_offloading)
- xdpg256: The eBPF program attached to the XDP generic hook with the default package headroom of 256 Bytes
- xdpg32: The eBPF program attached to the XDP generic hook with a custom package headroom set to 32 Bytes
- tc: The eBPF program attached to the TC hook
- xdpg32_dsa: The eBPF program attached to the XDP generic hook of the DSA switch with a custom package headroom set to 32 Bytes
- tc_dsa: The eBPF program attached to the TC hook of the DSA switch
Unfortunately, there is no performance gain when using the XDP generic mode with the default 256 Bytes packet headroom. TC is on the same level as Netfilter’s software offloading implementation. XDP generic with the custom 32 Bytes packet headroom is around 50 MBit/s faster.
The actual performance gain comes into play when attaching the eBPF program to the DSA switch. While XDP generic with 256 Bytes packet headroom is now at least faster than without offloading, XDP generic with 32 Bytes packet headroom is about 250 MBit/s faster than any other offloading, which means about 50% more throughput. TC is also a little bit faster, but there is not such a performance increase as for XDP.
I have created the following graphs using the Linux command line tool perf and scripts from the FlameGraph repository. They show how many CPU cycles Linux kernel functions used for the OpenWrt Firewall running without any offloading and the XDP generic with 32 Bytes packet headroom attached to the DSA switch.
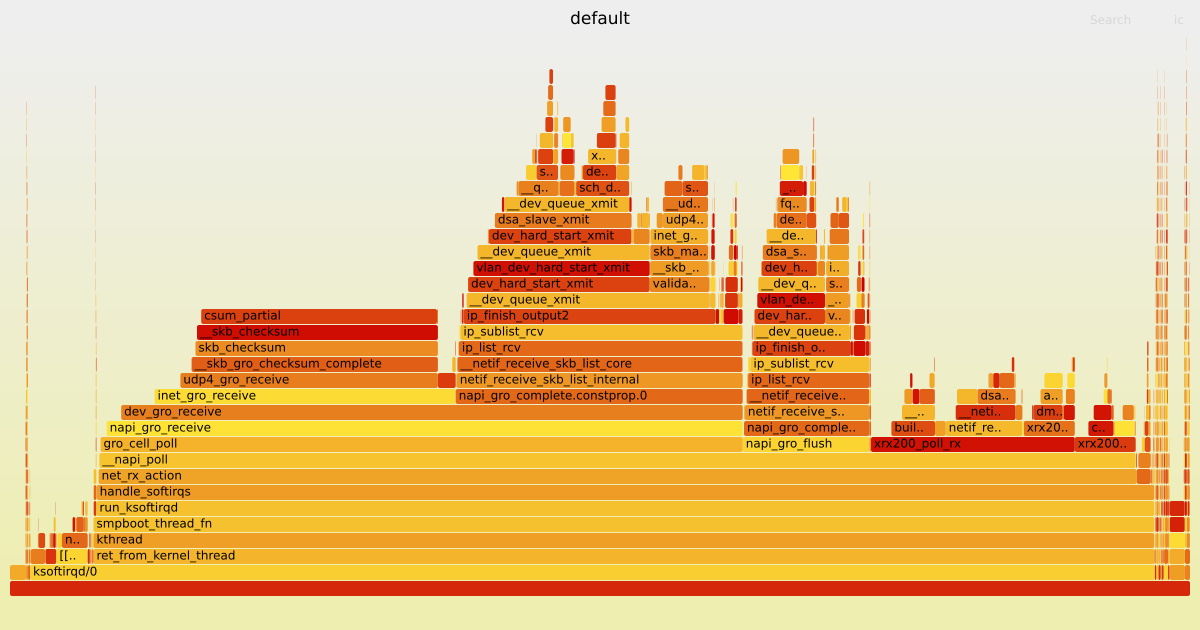 | 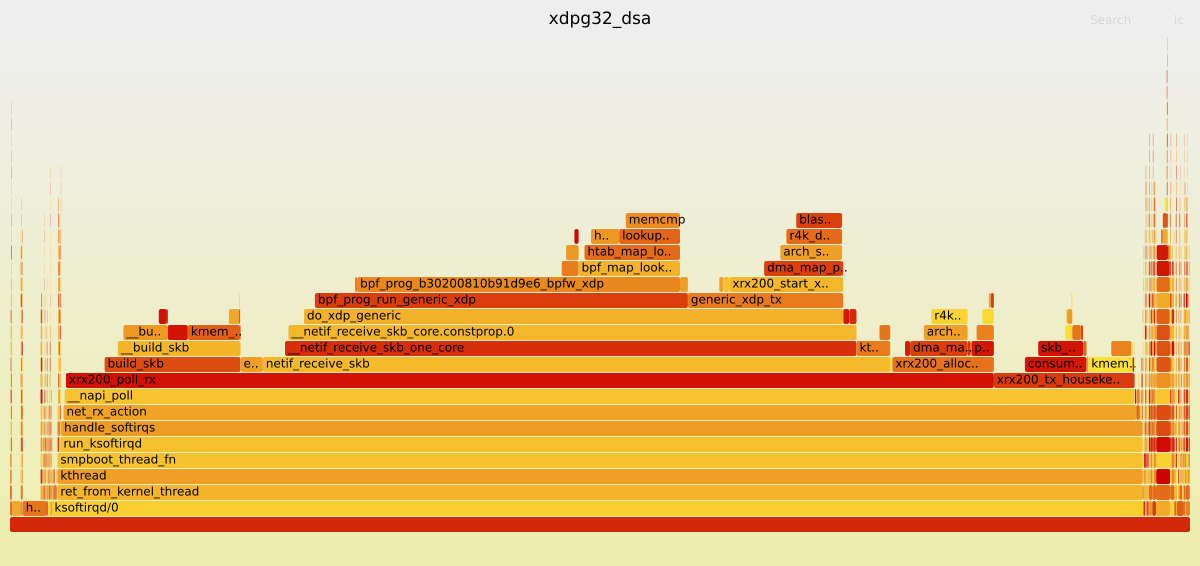 |
As you can see, since the eBPF program saves some Linux kernel function calls, the CPU can poll for more data via the xrx200_poll_rx function, which consequentially benefits the throughput performance.
Soon, I will also upload the graphs for the other measured parts and the package dropping performance into my already mentioned GitHub repository.
Concluding thoughts
While implementing this new Firewall offloading variant, I learned a lot of new things, not just about eBPF but also about the Linux kernel and network stack itself. Although it was not always easy, because I had to delve into Netlink first, for example, I also had much fun while coding.
As I have shown, the performance gain is somewhat mixed compared to OpenWrt’s current Firewall. To have a higher throughput, my XDP generic patch would need to be accepted for the upstream Linux kernel.
Finally, I would like to thank my mentor, Thomas, for giving me the chance to participate in GSoC 2024, and, the same goes for the OpenWrt core developer, Felix, for guiding me through the project. Furthermore, I appreciate that Andi and all GSoC involved Freifunk members make it possible to participate in such a project.
This concludes my GSoC 2024 project, but as I already mentioned, there is still some work to do. Should you have questions, do not hesitate to contact me. I hope you enjoyed the project as much as I did!