Hello! This post is about my progress so far while working on the new release of Pirania package for the new version of LibreMesh 2024.1 which runs on top of OpenWrt 23.5.3.
During last month there was a lot of interaction with the community via mailing lists and Matrix chat room.
Goals of this project
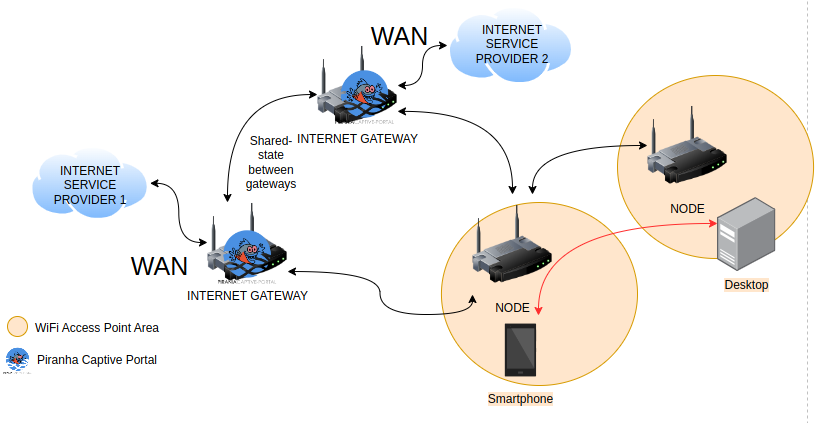
Pirania is a captive portal designed for community networks. It allows community members to create vouchers (or tickets ) in order to manage access to the internet. When a device access the network for the first time it redirects for the captive portal. Then, it’s needed to insert the voucher previously create by a community operator.
This promotes the sustainability of the network, since there’s costs involved in maintaining one.
What needs to be done
In version 22.03 of OpenWrt the new framework for packet processing and firewall was change from iptables (firewall3) to nftables (firewall4). Since Pirania captive portal uses iptables rules to redirect and allow/deny traffic from clients, there is a need to also update the rules that are created by captive-portal script.
First try
Here i will discuss what worked and what’s not.
Since i have a compatible router with Lime old version 2020.4, a TP-Link Archer c50 v1, i wanted to flash it and see Pirania functionalities in practice. Downloaded a pre-compiled firmware and flashed. It worked and the next step was to install Pirania and start it.
I got some errors (in feeds, while running “opkg update”, more specifically) while installing Pirania which i reported in Matrix chat. Community members helped me and confirmed that this error was not present in recent versions.
Error:
Collected errors:
opkg_download: Failed to download http://downloads.openwrt.org/releases/19.07.10/packages/mipsel_24kc/libremesh/Packages.gz, wget returned 8.
opkg_download: Failed to download http://downloads.openwrt.org/releases/19.07.10/packages/mipsel_24kc/profiles/Packages.gz, wget returned 8.
If you run into error during update and install process of Pirania, do the following:
“it should be enough to delete the libremesh and profiles rows in /etc/opkg/distfeeds.conf as the correct info should be already present in /etc/opkg/limefeeds.conf”
After changing this files, i was able to install Pirania package. But, forgot to install ip6tables-mod-nat and ipset, then my router entered in a weird state. Moving on..
Second try
One of the last GSoC there was a project that aim on easing the virtualization of LibreMesh. Available here. But since the contributor has not changed the requested modifications, it is still open the issue.
I was able to virtualize both Lime 2020.1 and 2024.1 versions. I used the scripts available in lime-packages/tools in order to emulate with Qemu software. Unfortunately wasn’t able to provide internet access to the node itself.
Third try
I had a Rocket M5 MX standing idle and decided to flash with latest version of LibreMesh on it. The installation was easy and is working fine. Just had to add the following line to /etc/config/lime-node in order to get a valid IP from my local network since it only have one physical interface, in order to install ipset package.
config lime network
config net portwan
option linux_name ‘eth0’
list protocols ‘wan’
Then, i was able to install the dependencies necessary to test my code.
Workflow
It’s really easy to test new software in Libremesh, since are usually scripts that need to be modified and can be run at run time. Just modify and upload the script to the working node and you are ready to go.
Code so far
I’m currently working on this branch, which link is below:
Next steps
The next step is to upload this script to a running node and see what happens.
There is a need to add more comments on the code and also with nftables is possible to enable remote logging of each rule that is executed, so will help a lot on debugging this script.
Also, i managed to setup a working node using VirtualBox. Maybe an alternative would be to create a VM with some Linux distribution and then connect it to the LibreMesh node, easing the process of testing.