Hello again, everybody! This is the Midterm follow-up blog post for my GSoC 2024 topic: “eBPF performance optimizations for a new OpenWrt Firewall.” It will cover how I started trying to solve the task, what the current implementation looks like, and what I will do in the upcoming weeks.
As a quick reminder: The project’s goal is to implement a new OpenWrt Firewall offloading variant using eBPF. Why eBPF? Because with eBPF, you can intercept an incoming data packet from the NIC very soon inside or even before the Linux network stack. After intercepting the packet with an eBPF program at the so-called XDP or TC hook, you can mangle it, redirect it to another or out of the same network interface, or drop it. Mangling the packet could mean, for example, applying possible Network Address Translation (NAT), adjusting the Time-To-Live (TTL), or recalculating the checksum(s).
The result should be that we see a performance increase, either by having a higher throughput, dropping packets faster, or lowering the CPU load.
Current implementation
The implementation consists of three components:
- The eBPF program which intercepts, mangles, and forwards or drops incoming data packets from a network interface
- A user-space program that attaches the eBPF program to the appropriate network interfaces and determines whether to forward a received packet and where to
- An eBPF map (in this case, a key-value hash map) so that the eBPF and user-space program can communicate with each other
Originally, I wanted to parse all OpenWrt Firewall rules and dump them into the eBPF map when the user-space program starts. When the eBPF program received a packet, it would try to match it with one of the parsed rules. But I had a few talks with the OpenWrt community and my mentor and concluded that this approach poses some problems:
- eBPF has limited looping support, but for rule matching, it is necessary to loop.
- OpenWrt uses the Netfilter framework as its firewall backend that has (too) complex features to implement in eBPF, like for example the logging of packets.
That is why we decided to go for a “flow-based” approach. When the eBPF program receives a packet, it creates a tuple from some crucial packet identifiers (Ingress interface index, L3 and L4 protocols, and source and destination IPs and ports). The program uses this tuple as the key for the eBPF hash map to signal the user-space program that it has received a packet for a new flow so that it can look up what the eBPF program should do with packets for that particular flow.
Until the user-space program responds, the eBPF program passes all packets belonging to that flow to the network stack, where the Netfilter framework processes it for now. In the meantime, the user-space program checks what the eBPF program should do with packets from that flow and stores the result inside the hash map as the value.
Connection Tracking must also be available because the to-be-implemented offloading variant should be stateful instead of stateless. I first thought about implementing it in the eBPF or user-space program. But then I realized I would somewhat reinvent the wheel because OpenWrt uses the Netfilter framework, which has a connection tracking implementation called nf_conntrack.
The Netfilter project provides an API through their user-space library libnetfilter_conntrack to add, retrieve, modify, and delete connection tracking entries. I am using this API in my implementation to check whether a conntrack entry exists for a packet flow. In the case of TCP, it only forwards packets while a connection is in the “Established” state so that Netfilter can still handle the opening and closing states of the TCP connections. In the case of UDP, the eBPF offloader starts forwarding packets on its own as soon as and as long as a conntrack exists. The user-space program meanwhile updates the timeouts for offloaded connections.
And there is a charm when using nf_conntrack: Such a connection tracking entry directly has NAT information available, so you don’t have to retrieve them by parsing OpenWrt firewall rules. Furthermore, this means that the forwarding part of the eBPF offloader can run independently of the Linux operating system used. It is only dependent on an OS that runs the Netfilter framework, including nf_conntrack.
Packet Forwarding
The following simplified activity diagram illustrates how incoming packets are forwarded by the current implementation of the offloader:
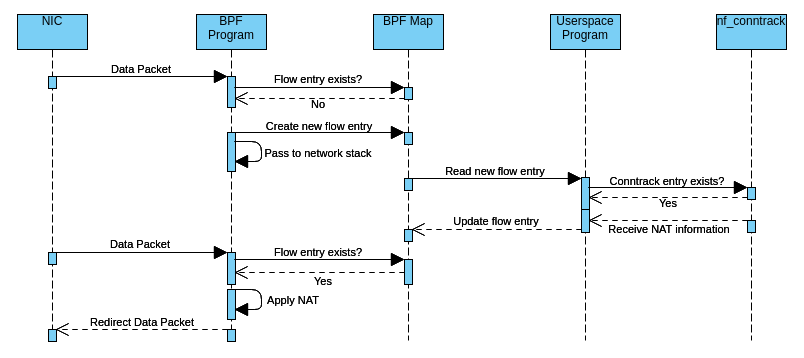
Here is a step-by-step explanation of what is happening:
- The eBPF program receives a data packet from the NIC for a not-yet-seen flow. It creates the packet tuple key and uses it to check whether an entry for that flow already exists inside the eBPF hash map. Since it hasn’t seen the flow yet, there is no entry, so the eBPF program creates a new empty entry inside that map to signal the user-space program. Meanwhile, it passes all the following packets of that flow to the network stack until the user-space program responds.
- When the user-space program wakes up, it retrieves the new flow entry from the map and checks through libnetfilter_conntrack whether a conntrack entry for the flow exists. If not, or the TCP state isn’t established, it doesn’t respond to the eBPF program (yet), so packets continue passing to the network stack. If there is an (established) conntrack entry, it also looks up inside that entry if NAT needs to be applied and, if so, calculates the checksum difference. Finally, it updates the flow entry accordingly to signal the eBPF program that it can take over now.
- When the eBPF program receives a new data packet for that flow again, it reads from the flow entry that it can forward the packet now, so it does possible NAT and checksum adjustments and redirects the packet to the target network interface. When there is a TCP FIN or RST or a conntrack timeout occurs, the eBPF program doesn’t forward the packet anymore and passes it to the network stack again.
Where to attach? Where to send?
There are two things I didn’t mention yet about the implementation:
- On which network interfaces should I attach my eBPF program?
- What is the next hop for the packet, i.e., to which output interface and neighbor to send it?
I implemented the latter within the user-space program using the Linux routing socket RTNETLINK. When I started to implement this, I performed the following three steps to determine the next hop:
- Send an RTM_GETROUTE message containing the packet tuple to determine the route type and output interface. I only offload unicast flows.
- Send an RTM_GETLINK message containing the output interface to determine the source MAC address.
- Send an RTM_GETNEIGH message containing the output interface and the destination IP to determine the destination MAC address.
Finally, the user-space program stores the output interface, source, and destination MAC address inside the flow entry. The eBPF program then rewrites the MAC header and redirects the packet to the output interface. But I wasn’t satisfied with that approach yet; I will explain the reason based on the following picture:
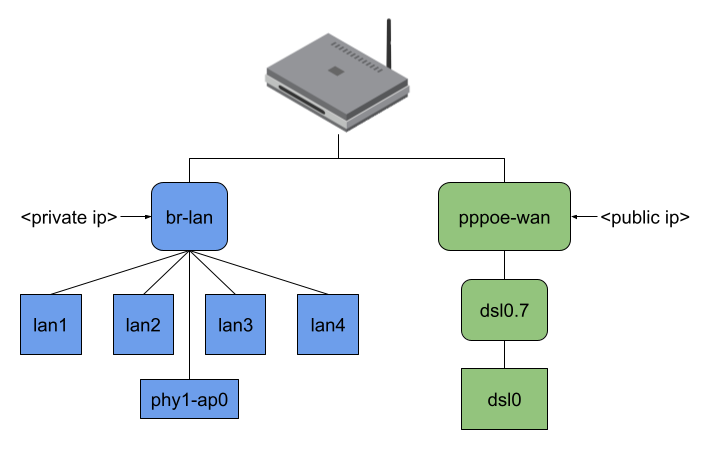
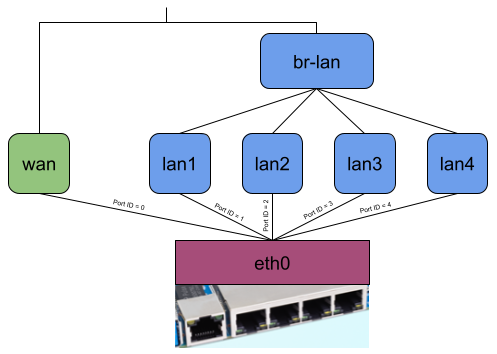
The picture shows the network interfaces of my AVM FritzBox 7530 running OpenWrt. As you can see, all four LAN ports of my private network and my WiFi are bridged (which is typical, I think, and generally default for an OpenWrt installation). My dsl0 WAN port has a Point-to-Point Protocol over Ethernet (PPPoE) interface on top to establish a VDSL connection to my ISP, which additionally requires tagged VLAN packets (dsl0.7).
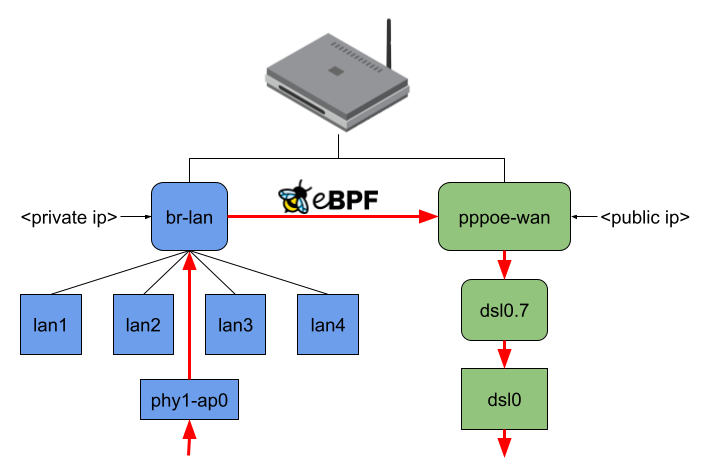
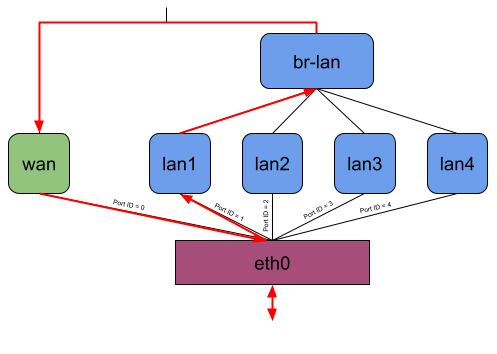
When no offloading is happening and, for example, my Notebook connected to phy1-ap0 would send traffic to the internet, the packets would travel through all shown interfaces except the LAN ports. (Figure 3). Regarding the eBPF offloader, the simple way would be to attach the eBPF program to the br-lan and pppoe-wan interfaces because I wouldn’t have to parse any additional L2 headers. The same goes when making routing decision(s) since you won’t have to query more interface information or push L2 headers. But the eBPF fast path would be minimal in that case. (Figure 4)
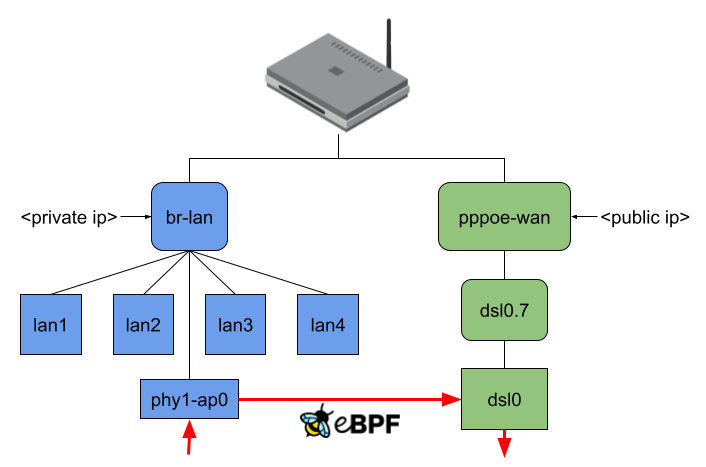
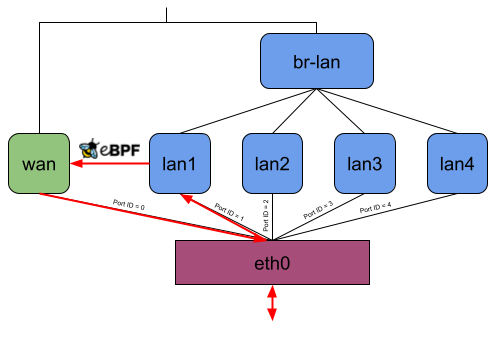
I thought this was not an acceptable solution for this project because the idea is to intercept an incoming packet as soon as possible. At the same time, the offloader should also send out packets at the lowest possible network interface. Therefore, the user-space program currently attaches the eBPF program to the lowest possible network interface and, while making the routing decision, also tries to resolve to the lowest possible network interface (Figure 5).
 |  |  |
The following flowchart shows how the user-space program currently does the next-hop determination:
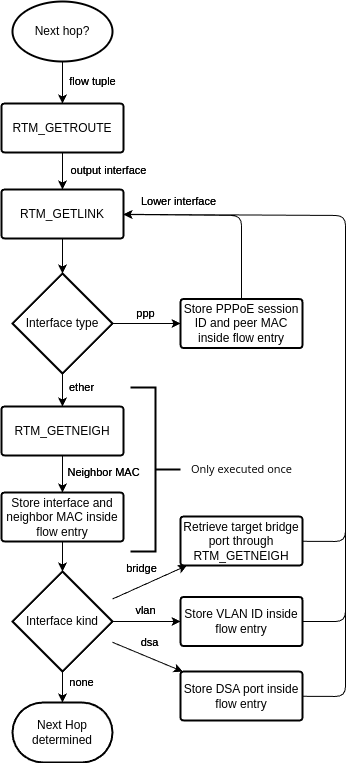
The eBPF program can currently parse the following headers of the respective layers. If it receives any packet containing a L2, L3, or L4 header not mentioned here, it passes the packet to the network stack.
- L2: VLAN (currently only one) and PPPoE
- L3: IPv4 and IPv6
- L4: TCP and UDP
DSA: Going one step further down
As you might have seen in the flowchart of Figure 6, the user-space program also parses DSA interfaces, which stands for Distributed Switch Architecture. Routers typically contain an Ethernet Switch for their LAN ports, which has a management port connected to an Ethernet controller capable of receiving Ethernet frames from the switch. While Linux creates a network interface for that Ethernet controller, you can observe that the DSA driver also creates network interfaces (DSA ports) for the front panel ports.
Ideally, when the switch and management interface exchange packets, they tag the packets with a switch resp. DSA tag, which contains the front panel port ID. When the management interface receives a packet from the switch, it can determine from the tag from which front panel port the packet comes and pass it to the appropriate DSA port/interface. When the switch receives a packet from the management interface, it can figure out from the tag to which front panel port it must send the packet.
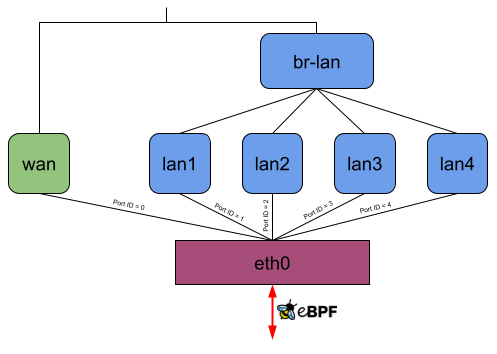
Let’s consider the following picture, which shows how OpenWrt on default settings uses DSA on a Banana Pi BPI-R64. The DSA switch resp. conduit is eth0 and lan1, lan2, lan3, lan4, and wan are the DSA ports resp. users.
Without offloading, a network packet sent from the private LAN to WAN would go through eth0, lan*, br-lan, wan, and eth0 again (Figure 8). When using the eBPF offloader without attaching to the DSA switch eth0, it is possible to avoid the bridge br-lan (Figure 9). But if you now attach the eBPF program to the DSA switch eth0, it can read and write the DSA tags of packets on itself, and the user-space program can then figure out which front panel received the package and to which one to send a packet. So when the eBPF program receives a packet on eth0, it can send it out of eth0 again without any intermediate interface (Figure 10).
 |  |  |
Although this has the disadvantage that an eBPF program isn’t “generic” anymore because you need to compile it for the DSA driver used by the target device, it has the potential to further increase the forwarding performance.
Work to do in the upcoming weeks
There are a few problems I have encountered, resp., thought of:
- I am unsure if nf_conntrack is sufficient for connection tracking because it isn’t possible to query conntrack entries based on the interface that received the packet. I think this can lead to collisions when different interfaces receive identical L3 and L4 flows.
- Unfortunately, it is currently impossible to update the nf_conntrack packet and byte counters. This might be patchable in the Linux kernel, but my current workaround is to turn off the counters because I think it is better to have no counters than wrong counters.
- I have shown that I retrieve PPPoE information in user space. The problem is that you cannot do that directly via Netlink since the interface attributes don’t provide PPPoE information. This is why I currently retrieve the interface’s link-local peer IPv6 address, convert it to a MAC address, and try to find that MAC inside the file “/proc/net/pppoe”, which is populated by the ppp daemon. I am anything but satisfied with that, but I haven’t found a better way yet.
Next to trying to solve those problems, the next milestone is to implement an eBPF package dropper into the offloader because, for now, it only forwards packets on its own. And then to finally make a performance evaluation of the implementation.
If you have questions, as always, feel free to ask them, and thank you for reading my Midterm update!
One thought on “GSoC 2024: eBPF performance optimizations for a new OpenWrt Firewall, Midterm update”