
Introduction
Hello everybody! My name is Til, and I am currently a Master’s engineering student at the University of Applied Sciences Nordhausen. For the past year, I focused on Linux network programming, especially eBPF, which brings me to my GSoC 2024 topic.
Over the years, the network stack has evolved to support new protocols and features. The side effect is that this introduces overhead and might hinder network throughput, especially on CPU-limited devices. One solution to overcome this is eBPF.
eBPF and its hooks
eBPF (extended Berkeley Packet Filter) is a technology within the Linux kernel that allows to dynamically re-program the kernel without recompiling or restarting it. Developers can write programs in C code, compile them to BPF objects, and attach them to several so-called hooks inside the Linux kernel. You can use two hooks to redirect incoming data packages to other NICs inside the Linux network stack: XDP and TC.
The XDP (eXpress Data Path) hook is located even before the network stack itself; its programs are attached to the driver of the NIC. That should make it the fastest eBPF hook throughput-wise for redirecting packages.
But there is a catch: NIC drivers must support this so-called “XDP native” mode. Otherwise, you need to attach them through the so-called “XDP generic” mode inside the network stack, which is significantly slower than native, which you will see soon in this post.
The TC (Traffic Control) eBPF hook is already located inside the Linux network stack but is driver-independent, so only the Linux Kernel needs to support it, i.e., compiled with the respective symbol enabled.
My GSoC 2024 project
My GSoC 2024 topic/goal is to introduce a new firewall software offloading variant to OpenWrt using eBPF. The idea is to intercept an incoming data packet from the NIC as early as possible inside or even before the network stack through XDP or TC. Then, for the actual firewall part, apply possible NAT (Network Address Translation) and drop or redirect the intercepted package to another network interface. That saves some CPU cycles and hopefully increases the network throughput on CPU-limited devices.
There are mainly three parts that need to be designed and implemented:
- The eBPF program which intercepts, modifies, and redirects or drops network packages
- A user-space program that attaches the eBPF program to the NIC(s) and checks the actual firewall rules
- A BPF map used for the communication between the BPF and the user-space program
The caveat of XDP generic
As mentioned, you can use the XDP generic mode if your NIC doesn’t support XDP native. Theoretically, the XDP generic mode should be faster than TC because the XDP generic hook still comes before the TC hook. But there is a problem: For XDP generic, the Linux kernel has already allocated the SKB for the network package, and XDP programs must have a package headroom of 256 Bytes. That means if the pre-allocated SKB doesn’t have a sufficient headroom of 256 Bytes, it gets expanded, which involves copy operations that effectively negate the actual performance gain.
I created a patch that, rather than making this package headroom value constant, creates a Linux kernel variable for that headroom exposed through the sysfs interface to Linux user space. It still has the default value of 256 Bytes, but then the user can explicitly lower the XDP generic package headroom according to his requirements.
The following table presents the head of a report generated by the Linux tool perf after running an iperf3 TCP test for 30 seconds through an MIPS router. I tested using an XDP generic package headroom of 256 Bytes first and then 32 Bytes. It shows how much CPU cycles this copy operation wastes.
26.91% ksoftirqd/0 __raw_copy_to_user
3.73% ksoftirqd/0 __netif_receive_skb_core.constprop.0
3.04% ksoftirqd/0 bpf_prog_3b0d72111862cc6a_ipv4_forward_func
2.52% ksoftirqd/0 __kmem_cache_alloc_node
2.32% ksoftirqd/0 do_xdp_generic
2.06% ksoftirqd/0 __qdisc_run
1.99% ksoftirqd/0 bpf_prog_run_generic_xdp5.70% ksoftirqd/0 bpf_prog_3b0d72111862cc6a_ipv4_forward_func
5.23% ksoftirqd/0 __netif_receive_skb_core.constprop.0
3.68% ksoftirqd/0 do_xdp_generic
3.02% ksoftirqd/0 __qdisc_run
3.00% ksoftirqd/0 bpf_prog_run_generic_xdpI will tidy up and try to submit that patch to the upstream Linux Kernel. Some people also tried similar approaches to fix the XDP generic performance by reducing the package headroom constant but never got accepted. So I hope my different approach has more success.
What to expect throughput-wise
To get some impression about the performance potential of eBPF, I have created a little BPF program that forwards all incoming IPv4 network packages. To test the program, I used an AVM FRITZ!Box 7360 v2 running OpenWrt with Linux Kernel version 6.6.30, whose CPU limits the throughput performance of its Gigabit ports. Then I grabbed a PC with two network ports, connected both ports with one port of the FritzBox respectively, and created two network namespaces at the PC to force the network traffic through the FritzBox. I used iperf3 to generate TCP traffic for 60 seconds for each tested setting respectively; you can find the results inside the following plot:
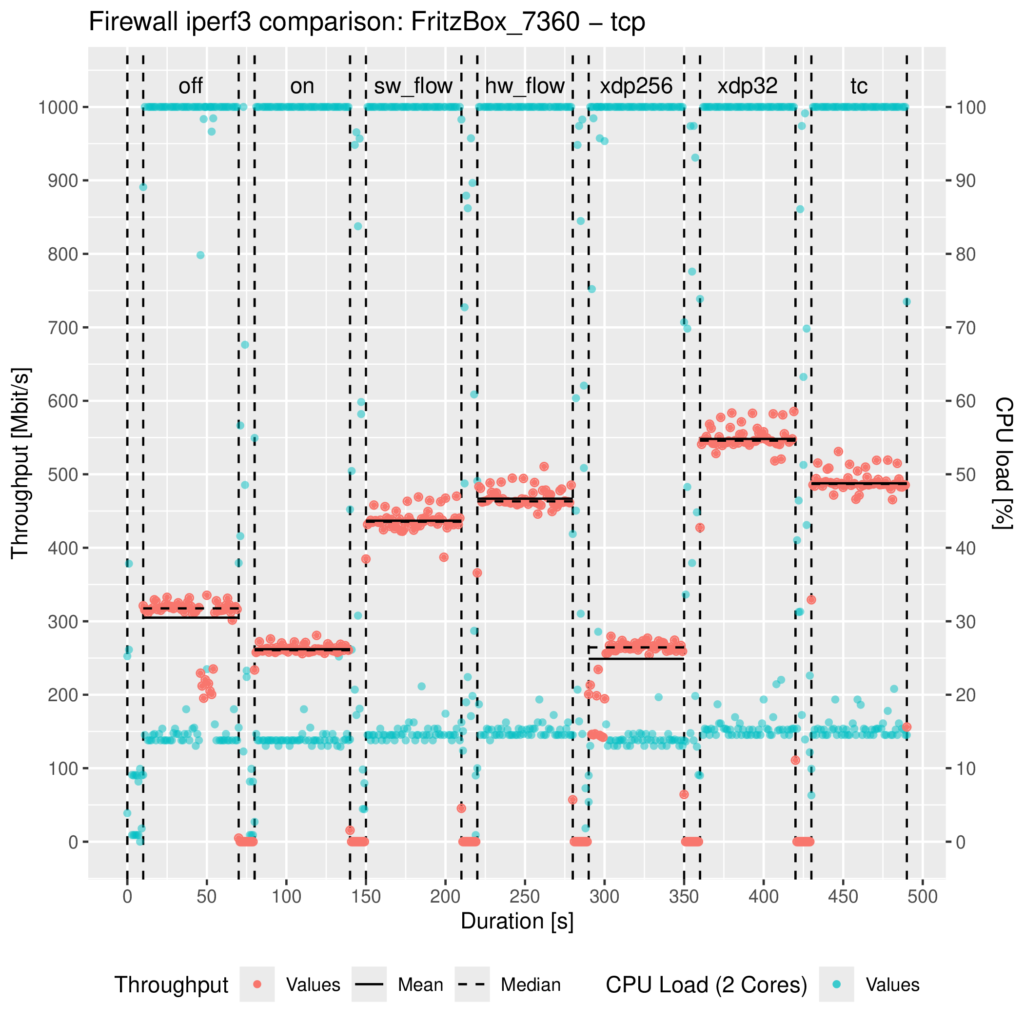
The settings/parts are the following:
- off: OpenWrt’s Firewall stopped (/etc/init.d/firewall stop)
- on: OpenWrt’s Firewall started but without any offloading enabled
- sw_flow: Netfilter’s software offloading enabled (flow_offloading)
- hw_flow: Netfilter’s hardware offloading enabled (flow_offloading_hw)
- xdp256: The eBPF IPv4 forwarding program attached to the XDP generic hook with the default package headroom of 256 Bytes
- xdp32: The eBPF IPv4 forwarding program attached to the XDP generic hook with a custom package headroom set to 32 Bytes allowed by my patch
- tc: The eBPF IPv4 forwarding program attached to the TC hook
Unfortunately, I couldn’t test XDP native yet because I don’t have any hardware around whose driver supports XDP.
As you can see and as I already mentioned, there is no performance gain from the XDP generic mode with the default 256 Bytes packet headroom due to the SKB re-allocation. Contrary to the patched XDP generic and TC, the network throughput about doubled compared to OpenWrt’s Firewall without any offloading.
Compared to Netfilter’s offloading implementations, there is also a performance gain, but admittedly only a small one. When we look at the Linux kernel source code here, this becomes plausible because the TC hook is located right before the Netfilter ingress hook. The XDP generic hook comes earlier than those two, even before taps (e.g., where tcpdump could listen).
So what’s next?
These are the upcoming milestones for the project:
- Creation of a user-space program for loading and communicating with the eBPF program
- Extending the user-space program with a firewall NAT/rule parser
- Extending the eBPF program to apply the parsed firewall configuration on incoming packages
- Evaluating the forwarding and dropping performance of the implementation
You can find the current eBPF IPv4 package forwarder, the XDP generic headroom patch, and the measurement and plotting script in my GitHub repository here: https://github.com/tk154/GSoC2024_eBPF-Firewall.
I will also upload the source code of the firewall there, which I am excited to implement in the upcoming weeks. I think the first small forwarding performance test already shows the potential of eBPF as a new offloading variant, and I haven’t even tested XDP native yet.
If you have any questions, don’t hesitate to ask them, and thank you for reading my first post.
One thought on “GSoC 2024: eBPF performance optimizations for a new OpenWrt Firewall”