I’ve set up a lot of services since planning out the data pipeline in June; the new infrastructure diagram looks like this:

So, I wrote a little Rust utility called json_adder which takes the JSON files and reads the data into a MongoDB collection. We also have a GraphQL server, running through Node.js, which can handle some (very) simple queries and return data. Many of these services are individually easy to set up, the tricky part is making sure everything works together correctly. This is what your favourite technical consultancies call “fullstack development”.
Data loading
The first change from the initial plan was to use MongoDB instead of MySQL as a database. MongoDB has a built-in feature for handling time-series data, which is what we’re working with. It integrates well enough with GraphQL, and since one of my mentors (Andi Bräu) works with MongoDB on a daily basis, there’s a lot of experience to draw upon.
Here is the Rust code for the utility which adds the data to the database, and here’s what it does:
- Read over each JSON file in the directory in a loop.
- Extract the last-modified time from each community in the file and do some conversion to BSON.
- Read the data into a struct, and add each object to a vector.
- Insert the vector into the MongoDB collection.
- GOTO next file.
When setting up the connection to MongoDB, the setup_db module will also check to create the collection if it doesn’t exist. This extra bit of logic is ready for when this has to be run in an automated process, which might involve setting up the database and filling it with data in one go.
I don’t have a binary to link here, and will write build instructions in future.1 On each commit which changes Rust code, Github Actions runs cargo check on the repository. When it comes to deploying this in reality, we can change that workflow to provide release builds.
At the moment it is a one-way process. You point json_adder at the data directory and it adds everything to the database. For future work, I’ll need a way to keep the database in sync, only add the files which have been modified, run it on a schedule. For now, it works fine.
GraphQL
Here is the GraphQL server code. Fetch the dependencies, in this order:
npm install express express-graphql graphql mongodb
The ordering of these is important.
Then, run npm start, and open http://localhost:4000/api in your browser, you should see the GraphQL IDE.
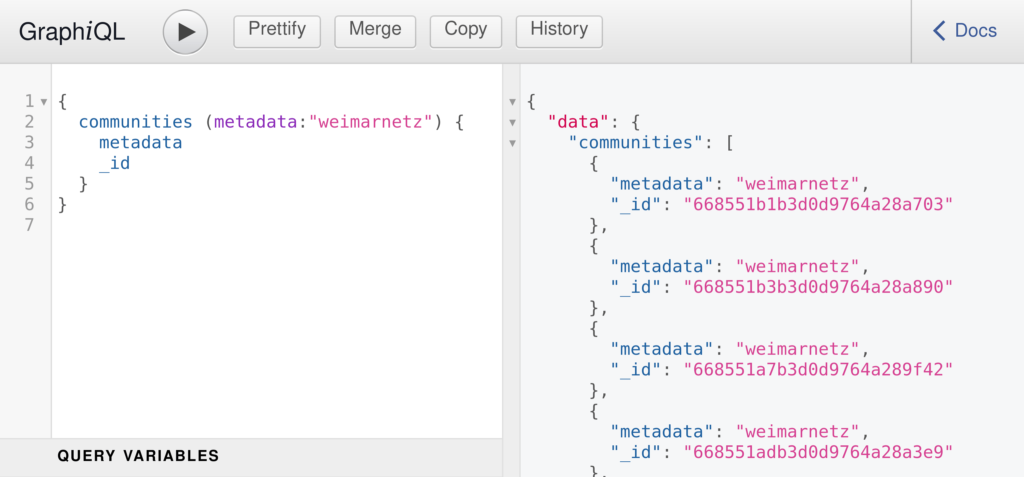
At the moment, the GraphQL can handle a query with an argument for metadata. I’ll build out the schema, and the resolver, to handle more arguments / more complicated queries. A lot of the documentation for GraphQL assumes a fairly simple schema, built for handling calls to a web app, which is slightly different from our case. The JSON Schema for the Freifunk API is not only quite long, it is also versioned, and newer versions are not necessarily backwards-compatible. I am going to sidestep this complexity by writing a GraphQL schema which only includes fields available in all versions. My first working example to try is a query which counts the number of nodes per community.
You’ll notice that the last step in in the pipeline is yet to be completed, I don’t have a visualisation to show. But, now that we can reliably pull data all the way through the pipeline, we’re almost ready to make some graphs.
- In the meantime, you only need to run
cargo buildin the json_adder directory. ↩︎