My project on community data visualisation is soon coming to a close; it’s time to review the work and what the outcomes were. The main goal of the project was to
build a [data] pipeline from the JSON directory through to some visualisations on a web page.
With some caveats, we’ve successfully achieved that. I made a tool (json_adder) which reads the JSON files into a MongoDB database, with a set of resolvers which provide a query interface, and finally some graphs which call the query interface and render the data using the d3 javascript library.
Beyond that, GraphQL was supposed to allow anyone else to
query the data for their own purposes.
I haven’t achieved this, partly due to the limits of GraphQL, which is better designed to service web apps than free-form queries. Queries are flexible only to the extent that they’re defined in the schema. Secondly, all of this is still only deployed locally, although it’s ready to deploy to production when needed.
At least the most difficult part of the project is over, the infrastructure is all there, and now the barrier to entry is much lower for anyone wanting to make a visualisation. New queries / visualisations can be contributed back to Freifunk’s vis.api.freifunk.net repository on Github.
Graphs
Top ten communities with the most nodes
This graph is very simple, top of the list here is Münsterland with 3,993 nodes at the time of writing. This doesn’t quite tell the whole story, because unlike city-based communities in this lineup, the Münsterland nodes are spread far and wide around Münster itself. Nevertheless, congratulations to Münsterland for the excellent network coverage!
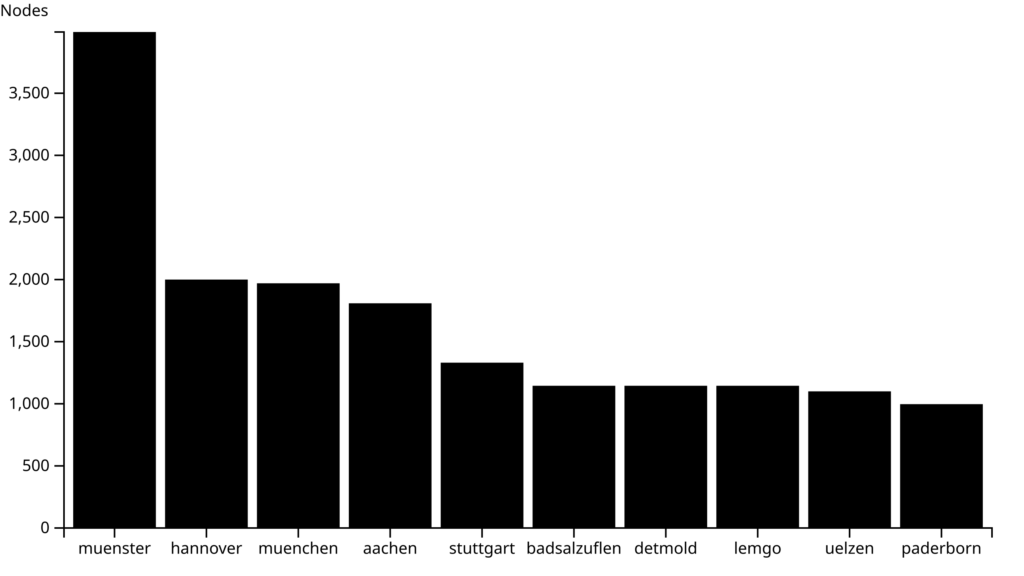
This bar graph was the first one I made, as a simple proof of concept. Since this worked well enough, I moved on to a line graph example, something which could take advantage of the time-series data we have.
Growth of the network over time
This graph shows the sum total of nodes across the network per month, from 2014-2024. The number of nodes grew rapidly from 2014-2017 before tapering off into a stable plateau. The high point ran through September and October 2019, with around 50,700 nodes at the peak.
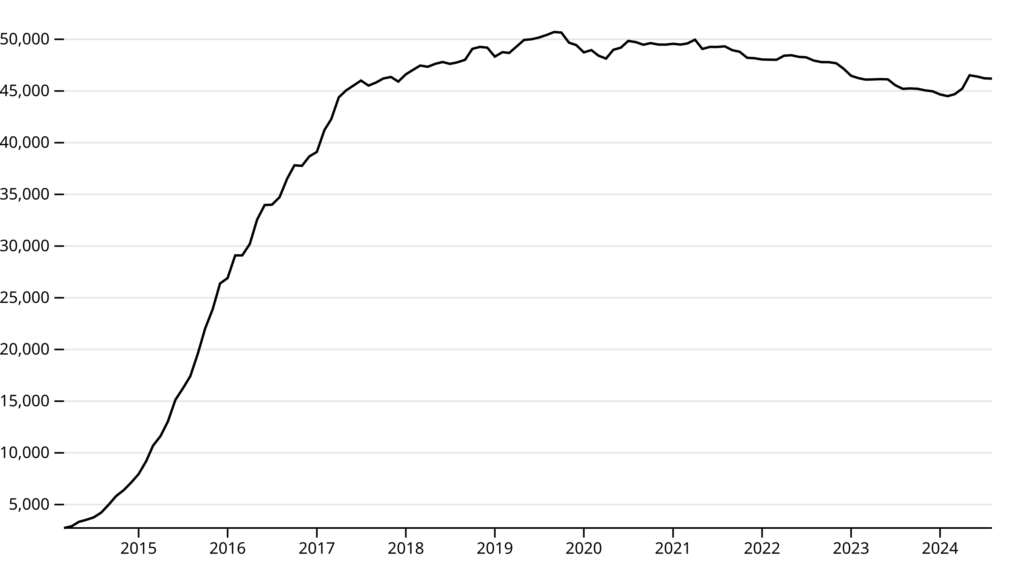
For some context on this curve, Freifunk as a project began in 2004, and only started collecting this API data in 2014. Part of the initial growth in nodes could be accounted for by new communities slowly registering their data with the API.
The query behind this graph became too slow after I’d imported the full 2014-2024 hourly dataset into MongoDB.1 Daily data was more performant, but was still unnecessarily granular, so what you see here is grouped by daily-average per month.
For shorter time periods, the data is still there to query by day or by hour, and this is something which could be worked into an interactive visualisation.
Routing protocols in use across the network
The next thing we wanted to see was the distribution of routing protocols. This graph is similar to the above, it counts the protocols used by each community every day, and averages the total each month.
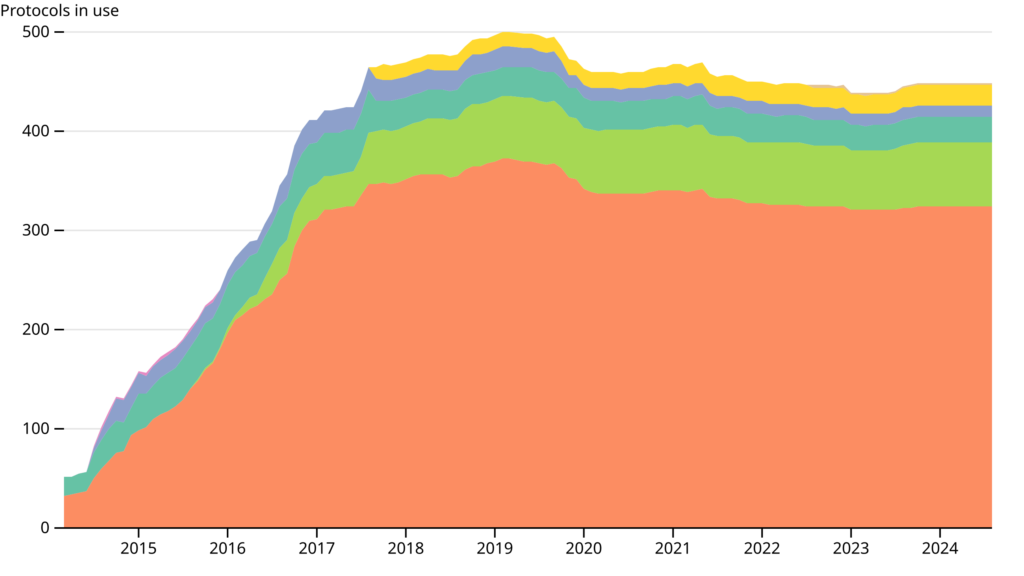
This graph doesn’t have a legend (#57), and the colours change on every page load (#56). I don’t know why the colours change like this, is this a common thing with d3? If anyone can resolve this, please help!
In the meantime, I have copied the d3 swatches example, to make a custom legend for the above graph.

We see that batman-adv is by far the most popular protocol, followed by 802.11s, which appears in the dataset in Duisberg in August 2015.
Remaining work
Everything here is all working locally, which leaves the main remaining task to try to deploy it somewhere for public use. We always had in mind that this would have to be deployed somewhere for public use eventually. So, thankfully we’ve already done some of this work and most of the services involved here can be easily packaged up and deployed to production. Andi is going to investigate webpack for bundling the javascript, trying to avoid having to procure (and especially maintain) another server.
Outstanding issues
There isn’t a Github issue for this, but the graph page is really a test page with only enough boilerplate HTML to show the graphs. The page would benefit from some styling, a small amount of CSS to make it look more… refined.
Visualisation ideas
- A word cloud of communities, scaled by node count (#46).
- A heatmap of communities across the network, showing geographical concentrations of nodes (#41).
- Hours of the day with most nodes online (#12).
Things I learned
This was my first time building a traditional web service end to end, from the database all the way through to a finished graph. In the end, the final three graphs do not look individually impressive, but a lot of work went into the process.
I took the opportunity to write the data loading code in Rust, and while I am proud of that, it took me a long time to write and wasn’t easy for others to contribute to. Andi rewrote this data loading code in Python much more quickly, and then made useful additions to it. Coding in a well-understood language like Python had advantages for project architecture which outweighed whatever technical arguments could be had around Rust.
In a similar vein, I learned how to write GraphQL schemas and queries, and arrived at the conclusion that GraphQL is not ideally suited for the kind of public query interface that I had in mind. The happy side of this lesson was that I ended up relying on MongoDB functions, and became better at writing those instead.
- As an aside, importing the full decade’s worth of hourly data made my (high end workstation) desktop computer really sweat. It was very satisfying to start the import, hear the fans on my computer spinning up to full speed, and physically feel the weight of all that processing. ↩︎