1. Introduction
Hi everyone! Welcome back to the final blog post in this series on Deep Q Network-based Rate Adaptation for IEEE 802.11ac Networks. The goal of this project is to build an intelligent rate control mechanism that can dynamically adapt transmission rates in Wi-Fi networks using Deep Reinforcement Learning.
Modern Wi-Fi networks need to dynamically pick a suitable Modulation and Coding Scheme (MCS) index based on ever-changing channel conditions. Choosing a rate that is too high relative to the channel quality (e.g., under high attenuation of interference) in a noisy channel typically leads to packet losses, while selecting a very conservative, low rate wastes valuable airtime, which ultimately harms the user experience. Traditional rate adaptation algorithms such as Minstrel rely on heuristics and fixed averaging windows, which may not generalize well across different environments or capture complex temporal relationships between link-layer feedback and optimal rate decisions.
In this GSoC project, we explored a Deep Reinforcement Learning (DRL) approach to rate adaptation for IEEE 802.11ac networks. Specifically, we implemented a Deep Q-Network (DQN)-based algorithm that learns to select optimal data rates directly from real-world observations derived from the ORCA (Open-source Resource Control API) testbed. We aimed to develop an intelligent controller capable of maximising throughput while maintaining a high transmission success ratio, without relying on handcrafted rules.
This blog walks through our journey: how we built an offline Wi-Fi rate adaptation environment from scratch, how we trained a DQN agent using real-collected packet-level traces, what technical challenges we faced along the way, and how the learned policy compares to traditional approaches.
Please feel free to check out the introductory and the mid-term blogs for more background details.
2. ORCA and Rateman [1]
To carry out this project, we leveraged ORCA, a kernel-user space API that exposes low-level transmission statistics and allows runtime control over Wi-Fi parameters including Modulation and Coding Scheme(MCS) index, defined by modulation type, coding rate, bandwidth, guard interval, and number of spatial streams. It enables remote monitoring and control from user space using the Remote Control and Telemetry Daemon (RCD). RCD is a user space package connecting ORCA endpoints to a bidirectional TCP socket, forwarding monitoring data and control commands.
ORCA allowed us to configure Access Points (APs), Stations (STAs), and capture real-time feedback such as Received Signal Strength Indicator (RSSI), frame attempt and success counts, and estimated throughput.
On top of ORCA, we utilize RateMan, a Python-based interface that simplifies per-STA rate adaptation and integrates cleanly with real-time experimental setups across multiple APs. It provides a clean abstraction to implement custom resource control algorithms in the user space.
This tight ORCA–RateMan integration allowed us to record realistic wireless behaviour under varying conditions, and later replay those traces in a simulated RL environment, effectively combining the benefits of real-world data with the repeatability and efficiency of offline learning.

Fig 1. Overview of the architecture of the user-space resource control using RateMan via ORCA [1]
3. Project Goals
The main goal of this project was to investigate the viability of Deep Reinforcement Learning for Wi-Fi rate adaptation and to build an end-to-end system capable of learning from real-world wireless behavior and deploying intelligent rate decisions on commodity hardware. To achieve this, we defined the following concrete objectives:
- Design a custom offline training environment tailored to Wi-Fi rate adaptation, where step-wise interaction is simulated using real packet-level traces instead of synthetic models.
- Leverage passively collected data where a fixed MCS rate is used throughout ORCA experiments. These traces — containing attenuation levels, RSSI values, success ratios, and throughput — serve as the experience source for training the DQN agent.
- Implement a Deep Q-Network (DQN) learning pipeline in PyTorch, chosen for its flexibility, fine-grained control over training primitives, and compatibility with Python 3.11 (required by ORCA-RateMan setup). Our implementation includes all major RL components, replay memory, epsilon-greedy agent, target network, and Bellman update, customized to our environment and thus can be considered a “from-scratch” integration, rather than relying on high-level RL libraries.
- Develop a DQN-based rate adaptation logic that plugs into RateMan’s user-space API, enabling learned actions (rate indices) to be sent to the real Wi-Fi firmware in a closed-loop fashion.
- Benchmark the learned agent against classical heuristics, with Minstrel-HT chosen as the baseline due to its widespread use in Linux Wi-Fi stacks.
- Ensure full compatibility with ORCA testbed hardware, so that the trained model and logic can be transitioned from offline simulation to real deployments without modifying the low-level radio stack.
These goals collectively shaped the backbone of our GSoC journey, from data collection and environment design, through learning and experimentation, to hardware-ready integration.
4. DQN Basics
A Deep Q-Network (DQN) is a reinforcement learning (RL) algorithm that uses deep learning to estimate the Q-function, which represents the cumulative reward of taking an action in a given state.

Fig 2. Illustration of state, action, and reward sequence in the interactions between the agent and environment within the reinforcement learning algorithm [4]
Environment Design
- State Representation: [rate, attenuation, RSSI, success_ratio] : In our offline training setup, each state is represented by a four-dimensional vector consisting of the transmission rate, attenuation, RSSI, and success ratio. The rate corresponds to the MCS index, which is directly obtained from the logged transmission events and defines the PHY data rate attempted by the access point. The attenuation reflects controlled channel conditions that were introduced during the experiments using programmable attenuators, thereby simulating realistic wireless environments with varying link degradation in decibels. The RSSI (Received Signal Strength Indicator) is extracted from the receiver-side logs and provides a direct measure of the signal quality experienced by the station, serving as an important feature that correlates link quality with achievable throughput. Finally, the success ratio is computed from ORCA’s transmission counters as the fraction of successful transmissions over total attempts within a logging interval, capturing the reliability of the chosen rate under the given conditions. By combining these four parameters, the state representation captures both the controlled experimental setup and the resulting link quality, offering the reinforcement learning agent the necessary context to make informed rate adaptation decisions.
- Action Space: Initially considered all valid 802.11ac rates, later narrowed down based on practical feasibility and dataset coverage.
- Reward Function: Directly proportional to achieved throughput, while penalizing low success ratios (to discourage risky selections).
Agent and Learning Logic
- The agent uses ϵ-greedy as the exploration strategy that selects random actions with probability ϵ, otherwise selects the action with the highest predicted Q-value.
- Replay Buffer: Stores past experiences to break temporal correlations during training.
- Q-Network: A neural network parameterized with weights, mapping states to Q-values for every possible action.
- Target Network: A periodically updated copy of the Q-network to stabilize learning.
The agent iteratively samples experiences from the replay buffer and minimizes the Bellman loss, learning to associate long-term throughput gains with specific rate decisions under varying channel conditions.
Hyperparameters
The following hyperparameters were used during training:
- Discount factor (γ = 0.99): Balances immediate vs. future rewards. A high γ ensures the agent values long-term throughput instead of being greedy about short-term gains.
- Batch size (128): Number of experiences sampled from the replay buffer for each training step. Larger batches provide more stable gradient updates.
- Learning rate (1e-3): Controls the step size in updating network weights. A moderate learning rate ensures steady convergence without overshooting.
- Target update frequency (1000 steps): Determines how often the target network is updated with the Q-network’s weights. This reduces instability during training.
These hyperparameters ensure that the agent can generalize effectively from past experiences, avoid instability in Q-value estimation, and steadily converge toward optimal rate adaptation behavior.
5. Setup
For data collection, all experiments were conducted using two RF isolation boxes, one housing the ORCA-controlled Access Point (AP) and the other housing the Station (STA). The antenna ports of the AP and STA were connected via RF cables, with an Adaura AD-USB4AR36G95 4-channel programmable attenuator placed in between. Figure 1 provides a visual illustration of the setup.
This enclosure ensures a controlled wireless environment free from external interference, noise, and multipath effects. This allowed us to precisely evaluate how different MCS rates behave purely under varying attenuation levels.
Using programmable RF attenuators inside the box, we could emulate varying channel qualities in a deterministic way, while keeping other environmental variables fixed. This level of controllability is vital when generating training data for RL agents, as it guarantees that observed effects in performance are attributable primarily to rate selection and attenuation.
5.1 Data Collection
- Hardware/Testbed: ORCA nodes with RateMan control loop.
- Configuration: AP ↔ STA, static distance, attenuation swept gradually.
- Rates Tested: One rate group per experiment — e.g., Group 12 (120-128(hex) ⇒ decimal 288–296). Each group contains indices for different modulation type and coding rate, for fixed number of spatial streams, bandwidth, and guard interval. (more details in the mid-term blog)
- Parameters Extracted (from raw trace files):
rate, attenuation (dB), RSSI (dBm), theoretical_data_rate (Mbps), and number of attempted and successful transmissions. - Calculated Features:
- success_ratio = successful / attempted
- Used to compute state vectors and rewards for the offline RL environment.
- success_ratio = successful / attempted
5.2 Reward Function Variants Tested
Designing the reward was critical, as it directly influenced which rates the agent learned to prefer:
- reward = success_ratio × throughput
- Simple and intuitive, but failed to penalize high rates that recorded zero successes. These rates often had theoretical throughput, misleading the agent into over-selecting them.
- reward = (2 × success_ratio – 1) × theoretical_data_rate
- Integrated punishment for unreliability, but was too harsh on high rates, causing the agent to ignore them even under good channel conditions.
- Attenuation-aware penalty
- Penalizes failed transmissions, scaled by attenuation, so the agent learns to accept occasional failures at low attenuation (where high rates are viable), but becomes conservative at high attenuation, where such attempts are wasteful.
- Sample code:
- if success_ratio == 0:
- penalty_scale = 1.0
- if attenuation > 55:
- penalty_scale = HIGH_ATTEN_REDUCTION
- reward = -min(theoretical_throughput, MAX_FAIL_PENALTY) * penalty_scale
All generated experience tuples were stored in .pkl files, one per rate group experiment. These served as the replayable dataset for our offline DQN training pipeline.
5.3 Environment Design
Offline Training Environment
To train our DQN agent, we constructed a simulated environment that replays experiences extracted from the .pkl trace files collected on the ORCA testbed. At each time step, the environment provides the state representation [rate, attenuation, RSSI, success_probability], exposes the available rate indices from the corresponding group as the action space, and computes the reward using the designed function described in Section 5.1.
Training proceeds entirely offline: the agent never interacts with real hardware during this stage. Instead, the training loop samples batches of transitions from a replay buffer, computes the Bellman loss, and iteratively updates the Q-network weights. This approach allowed us to leverage large amounts of pre-recorded data efficiently while avoiding the practical limitations of online learning.
Post-Training Simulation Environment
After training, the learned DQN models were evaluated in a separate simulation environment designed to mimic—but not directly replay—the collected traces. Unlike the training phase, the evaluation relies solely on the learned Q-function. Given the current attenuation level, the DQN selects an action (rate index), and the simulator generates the corresponding success probability and reward using the theoretical data rate of that action to approximate real-world performance.
This evaluation loop enabled us to benchmark the generalization ability of the DQN policy, independent of the training samples, and to assess its rate-selection behavior under different attenuation conditions before attempting live deployment.
5.4 Deployment via Rateman (Live Testing Environment)
Once satisfactory results were obtained in simulation, the trained DQN policy was deployed inside the RF shielding box, where the real wireless medium served as the environment. In this setup, RateMan acted as the control and monitoring interface to ORCA. At each decision interval, RateMan queried the Python-based DQN model for the next rate index, pushed the chosen rate to the ORCA firmware, and collected live link-layer statistics such as attempted transmissions, successful packets, and RSSI. These statistics were then fed back to the DQN logic for subsequent decisions.
This creates a closed control loop:
DQN policy → RateMan control API → ORCA hardware → real radio environment → feedback to DQN.

Fig 3. Current DQN Implementation
5.5 Model Evaluation
Following the successful integration of the trained DQN with the RateMan control loop, we wanted to test the efficiency of the trained DQN model on a simulated environment that mirrored the real wireless testing setup.
To visually inspect whether the agent was making sensible decisions, we generated heatmaps showing which rates were chosen across different attenuation values, revealing if the DQN correctly preferred higher rates at lower attenuation and more conservative rates as channel quality degraded.

Fig 4. Rate-Attenuation(55dB) Heatmap
Figure 4 illustrates a heatmap indicating how each of the 232 available rates behaves at that attenuation. The success ratio is indicated by the background color of each cell, with purple and red being the extreme positive and null successes. Each cell also contains its theoretical data rate, upon which our reward system is based. So, in this case, we would expect the DQN model to select the rate (4,80Mhz, 400ns), (16-QAM,¾) as its theoretical rate is the highest among the successful rates.
We then plotted reward curves over multiple episodes to assess overall stability and performance. Figure 5 expresses the efficiency of the trained DQN model to generate ample rewards (based on theoretical data rates) throughout the entire period.

Fig 5. Distribution of rewards over time
After the confirmation of positive rewards, we conducted live experiments in the shielding box to evaluate the real-world behaviour of the learned rate adaptation policy.
For each run, we swept attenuation levels and continuously logged:
- Rate index selected by the (Deep Q-Network based Rate Adaptation) DQN-RA
- Expected throughput, success probability, and reward
- Corresponding attenuation (dB) and RSSI
Then we benchmarked the distribution of selected rates against manually known “optimal” rates for different attenuation regions using the above-described heatmaps.
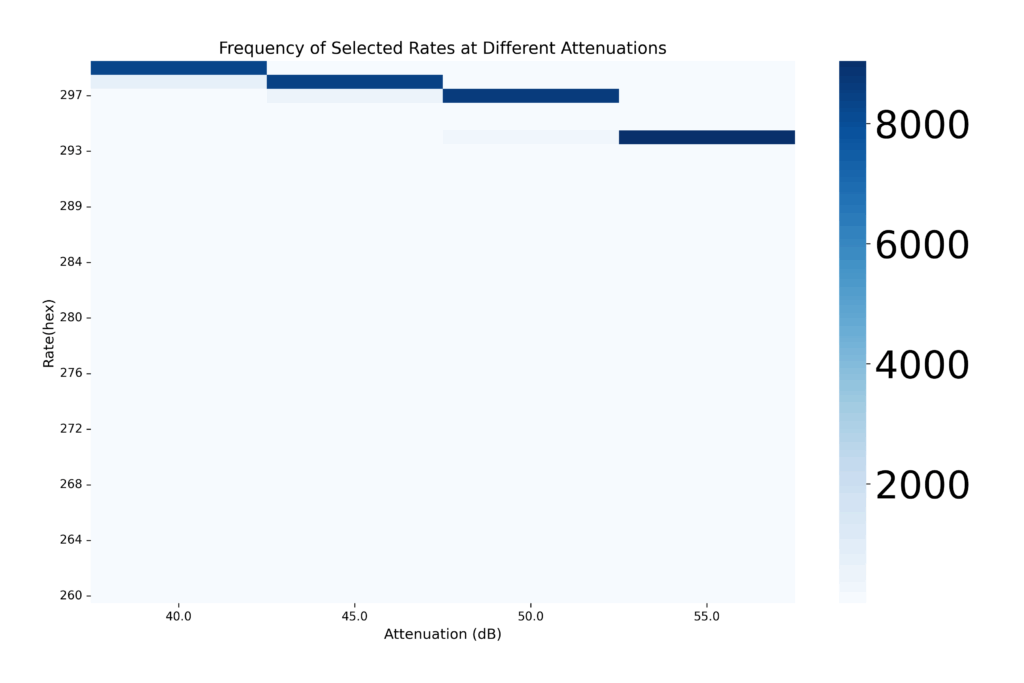
Fig 6. Selected Rates at different attenuations
In Figure 6, we can observe the frequency of different rates selected at each attenuation.
With the help of the heatmaps described above, it was confirmed that the DQN model was indeed selecting the highest feasible rates and thus maximizing its rewards.These analyses helped verify that the DQN was not only compatible with RateMan in deployment, but was also making reward-maximising, context-aware decisions in a live RF environment.
Results
The performance of the deployed DQN agent was assessed by analysing its rate-selection behaviour under varying attenuation levels compared to minstrel_ht.
We ran experiments with minstrel_ht and DQN-Rate-Adaptation under similar settings.
For the DQN, scatter plots and heatmaps revealed clear switching behaviour with higher MCS rates chosen at low attenuation (strong channel conditions), and lower, safer rates selected as attenuation increased.
Figures below summarize the comparison against minstrel_ht.

Fig 7. Rate Selection for Minstrel_HT vs. DQN_RA
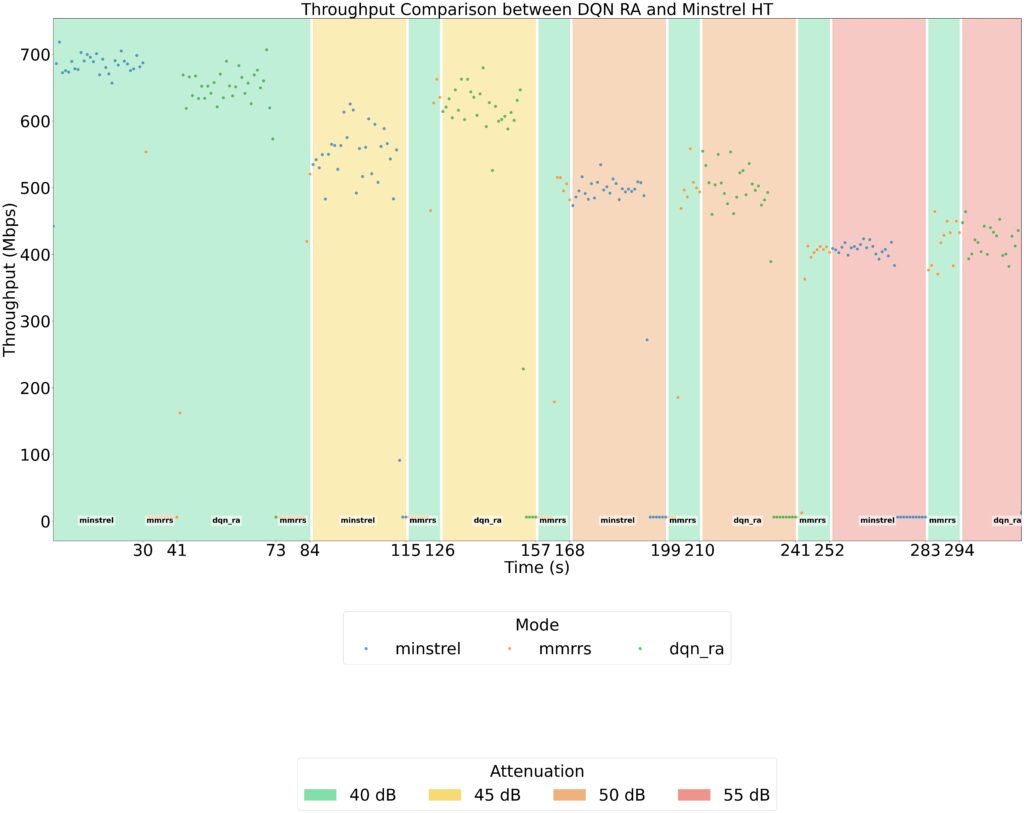
Fig 8. Measured Throughput for Minstrel_HT vs. DQN_RA
Key Observations
Our experiments revealed several important insights into the behavior of the DQN-based rate adaptation algorithm. First, the learned policy adapts intelligently to changing channel conditions, consistently producing more robust rate decisions than Minstrel_ht, particularly in the mid-attenuation region where Minstrel tends to select much lower rates. This highlights the ability of the DQN agent to capture patterns in the environment that a heuristic-based approach may overlook.
When comparing throughput performance, both DQN-RA and Minstrel_ht achieve similar results at 40 dB attenuation for the same rate selections. However, as attenuation increases, DQN-RA consistently outperforms Minstrel_ht, achieving noticeable throughput gains at higher link attenuation levels. This suggests that reinforcement learning can provide tangible benefits in more challenging channel conditions.
Another interesting observation is that the agent does not simply converge to the highest theoretical MCS indices. Instead, certain rates were consistently favored because they offered stable real-world performance across a broader operating range. This indicates that the DQN agent is learning meaningful, deployment-relevant strategies rather than just overfitting to peak values.
Finally, the experiments demonstrated the importance of action space design. When the agent was allowed to explore the full set of supported rates, the learning process became significantly harder, leading to slower convergence and repeated suboptimal choices. In contrast, reducing the action space to task-specific subsets improved both practicality and performance, suggesting that action-space reduction is a critical consideration for real-world deployments of learning-based rate adaptation.
7. Challenges Faced
Throughout the development and deployment of the DQN-based rate adaptation system, several practical and algorithmic challenges emerged:
Choosing an Appropriate Training Strategy
Designing an effective learning pipeline required striking a balance between offline replay-based training (easy to scale but limited by logged data) and online interaction (more realistic but time-consuming and hardware-dependent). Selecting the right blend was critical to ensure real-world deployability without overfitting to historic traces.
Impact of Action-Space Size
We observed that the size of the rate action set had a significant impact on learning stability. Training with a larger action space caused Q-values to be noisy and slowed convergence, whereas a reduced, experiment-specific set led to faster and more consistent learning.
Comparison Runs (Large vs Small Action Space)
Side-by-side offline training runs confirmed that smaller action spaces enabled the agent to focus on realistic rate assignments, whereas larger action sets often caused it to explore impractical high-MCS actions that performed poorly in practice.
Dangerous High-Rate Actions
Certain MCS indices provided very high theoretical throughput, which yielded high Q-values early in training. But these rates were actually rarely successful under higher attenuation, misleading the agent unless penalised correctly.
Reward Shaping Difficulties
Extensive experimentation was required to design a reward function that rewarded aggressive, high-performing rates under good conditions, while heavily penalising them under poor channel conditions. Several hand-crafted reward structures were tested before arriving at a formulation that maintained a healthy spread of Q-values across the action-space and prevented domination by overly optimistic, unreliable rate choices.
These insights highlight the importance of domain-aware RL design, where subtle choices in environment, rewards, and action spaces dramatically influence real-world behaviour.
8. Limitations
While the project successfully demonstrated the feasibility of DQN-based rate adaptation, several limitations were observed:
- Large Action Space Challenge
- Training with all 232 supported 802.11ac rates caused unstable learning and poor convergence
- Restricted Evaluation Range
- Experiments were limited to four attenuation levels (40, 45, 50, 55 dB), which may not fully capture the dynamics of real-world wireless environments.
- Hyperparameter Sensitivity
- Training stability was found to be sensitive to hyperparameter choices, highlighting the need for systematic hyperparameter tuning.
- Offline Trace Dependence
- The agent relied heavily on pre-collected traces, which may limit adaptability to unseen channel variations during deployment.
9. Future Work
Moving forward beyond GSoC, our objective is to progressively expand both the dataset and action space, ultimately scaling back up toward full-rate adaptation across all supported MCS indices.
Looking ahead, there are several promising directions for future work. More diverse traces can be gathered across wider attenuation ranges and channel conditions to improve generalization. Another approach can be online learning, allowing the agent to continuously adapt to real-time conditions rather than being confined to pre-collected data. Finally we can also explore advanced architecture such as Multi-headed DQNs to handle the large number of action spaces and hopefully enhance stability and performance.
This staged strategy will help maintain training stability while inching closer to a fully generalizable DQN-driven rate control mechanism for Wi-Fi systems.
10. Conclusion
The project achieved its goal of developing and deploying a DQN-based rate adaptation policy on commodity Wi-Fi hardware. By reducing the action space to a manageable subset, the agent was able to learn context-aware policies that aligned with real-world performance expectations.
Importantly, this work advances beyond earlier DRL-based rate control proposals such as DARA [2] and SmartLA [3], which focused on limited subsets of rates (often <10 actions), small variations in RSSI, and did not perform live hardware deployment on ORCA-like setups. In contrast, our system trains on genuine 802.11ac traces, integrates seamlessly with RateMan, and is fully deployable on real hardware, achieving live closed-loop decision making.
I am deeply grateful to have had the opportunity to be a part of this GSoC project. This experience has been both challenging and immensely rewarding, allowing me to explore the intersection of deep reinforcement learning and wireless networking in a real-world setting.
I would like to sincerely thank my mentors for their invaluable guidance, patience, and support throughout the journey. Their insights and encouragement have been crucial in navigating both technical challenges and research decisions.
Working on this project has been a truly enjoyable experience, and I am thankful for the chance to contribute to advancing intelligent Wi-Fi rate adaptation. This opportunity has not only expanded my technical skills but also deepened my appreciation for collaborative, cutting-edge research.
References
1. Pawar, S. P., Thapa, P. D., Jelonek, J., Le, M., Kappen, A., Hainke, N., Huehn, T., Schulz-Zander, J., Wissing, H., & Fietkau, F.
Open-source Resource Control API for real IEEE 802.11 Networks.
2. Queirós, R., Almeida, E. N., Fontes, H., Ruela, J., & Campos, R. (2021).
Wi-Fi Rate Adaptation using a Simple Deep Reinforcement Learning Approach. IEEE Access.
3. Karmakar, R., Chattopadhyay, S., & Chakraborty, S. (2022).
SmartLA: Reinforcement Learning-based Link Adaptation for High Throughput Wireless Access Networks. Computer Networks.
4. State-Action-Reward Diagram
https://www.researchgate.net/figure/llustration-of-state-action-and-reward-sequence-in-the-interactions-between-the-agent_fig1_381250814