Introduction
Hi everyone! I’m Raul Shahi, a Master’s student in Computer Engineering for IoT Systems at Nordhausen University of Applied Sciences, Germany. I’ve been working as a Research Assistant at my university, where I’ve been developing and experimenting with tools for Wi-Fi resource control.
I was also a part of GSoC 2024, where I worked on Throughput-based Dynamic WiFi Power Control for Real Networks. Please feel free to check this blog for the project.
For GSoC 2025, I will work on building a Deep Q-Learning (DQN)-based Wi-Fi Rate Adaptation algorithm for IEEE 802.11ac networks. This project leverages machine learning techniques to address the limitations of traditional rate adaptation algorithms in dynamic wireless environments. In this blog post, I’ll walk you through the motivation, approach, and expected outcomes of the project.
Motivation
Rate Adaptation(RA) in Wi-Fi networks refers to the selection of the optimal Modulation and Coding Scheme (MCS) to maximize data throughput in the presence of varying channel conditions. As wireless links experience fluctuations due to interference, mobility, and environmental factors, a robust RA mechanism is crucial for achieving high performance. RA is a MAC-layer task that must respond rapidly and intelligently to the dynamic nature of wireless channels. The complexity of this task continues to grow with the expansion of the MCS index space, advancements in Wi-Fi standards, and increasingly heterogeneous network topologies.
Several RA algorithms have been developed to address this challenge, with Minstrel-HT being the default RA algorithm in the Linux kernel. While Minstrel-HT performs well in relatively stable conditions, its responsiveness and decision quality tend to degrade in rapidly changing environments, often resulting in sub-optimal throughput and increased latency. Study such as MAC-Layer Rate Control for 802.11 Networks: A Survery [2] provides comprehensive overviews of these limitations.
Recent research has explored the application of Deep Reinforcement Learning (DRL) to Rate Adaptation (RA), showing potential performance improvements over traditional heuristic-based methods by learning RA policies directly from network statistics such as Signal-to-Noise Ratio (SNR), throughput, or ACK failures [3, 4]. However, most of these SOTA approaches are evaluated solely in simulated environments (e.g., ns-3 or MATLAB), lack validation on commercial off-the-shelf (COTS) hardware, and often consider outdated standards like IEEE 802.11n. Additionally, they usually operate on a reduced set of MCS indices or simplified network models, which limits their applicability to modern Wi-Fi deployments with complex topologies and diverse traffic patterns.
Moreover, implementing DRL in practical systems presents inherent challenges: DRL agents typically require substantial computational resources and time for training, making real-time learning and deployment on embedded devices difficult. These issues hinder the direct transfer of DRL-based RA algorithms from simulation to real-world applications.
This project aims to bridge this gap by leveraging the ORCA API and RateMan framework to deploy and evaluate a DRL-based RA solution on real IEEE 802.11ac hardware, with minimal overhead and full observability into transmission statistics.
To overcome the lack of practical platforms for evaluating advanced RA algorithms, this project builds upon ORCA[1], a kernel-user space API that exposes low-level transmission statistics and allows runtime control over Wi-Fi parameters such as MCS, bandwidth, and spatial streams.
On top of ORCA, we utilize RateMan[1], a Python-based interface that simplifies per-STA rate adaptation and integrates cleanly with real-time experimental setups across multiple access points (APs). This setup offers a testbed that is both flexible and extensible, making it well-suited for developing and evaluating DRL-based RA algorithms.
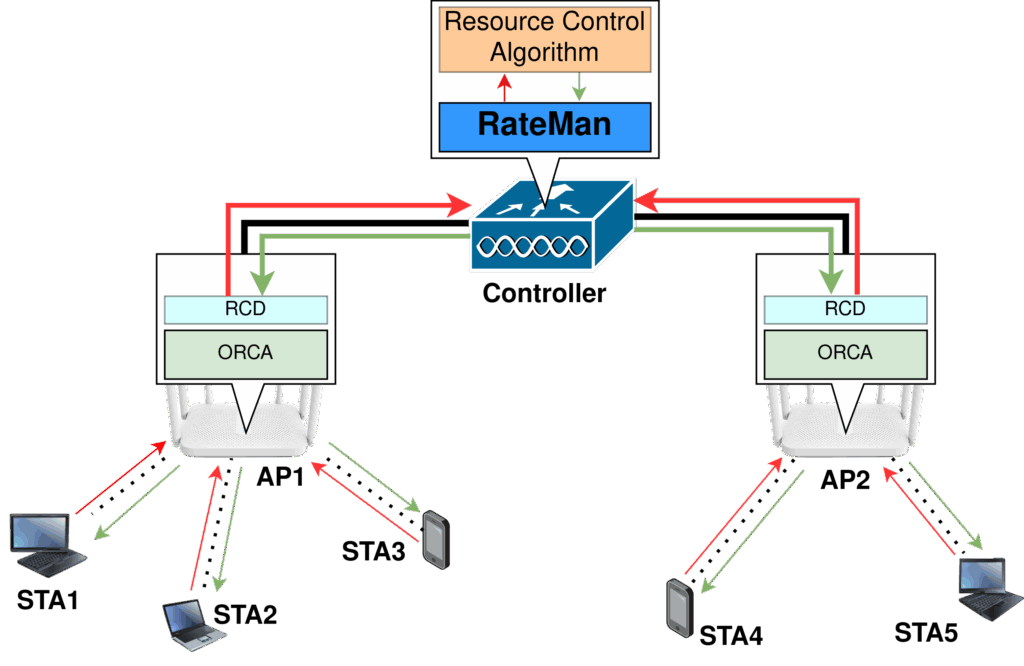
Fig 1. Overview of the architecture of the user-space resource control using RateMan via ORCA[1]
This setup abstracts away kernel-level complexities, allowing developers to focus on high-level algorithm design for rate adaptation. By integrating Deep Reinforcement Learning (DRL) into this user-space framework, we can overcome the limitations of prior work, such as reliance on simulation tools, limited rate sets, or outdated standards and evaluate learning-based approaches directly on commercial off-the-shelf (COTS) Wi-Fi hardware. This bridges the gap between theoretical advancements and practical deployment, enabling reproducible and scalable experimentation in real environments.
Methodology
A Deep Q-Network (DQN) is a reinforcement learning (RL) algorithm that uses deep learning to estimate the Q-function, which represents the cumulative reward of taking an action in a given state.

Fig 2. Illustration of state, action, and reward sequence in the interactions between the agent and environment within the reinforcement learning algorithm [5]
We’ll use the ORCA API and Rateman as our experimental framework. Here’s a high-level overview of our approach:
- DQN Agent Design: The agent observes channel statistics (e.g. throughput, retries, SNR) and learns to select optimal data rates.
- Environment Feedback: The environment will be represented through Rateman, which interfaces with ORCA to provide real-time feedback in the form of Transmit Status (txs) events from OpenWrt-based nodes. These txs events encapsulate per-frame transmission statistics such as retry count, transmission rate (MCS), and success/failure outcomes. This detailed low-level feedback serves as the observable state for our learning agent, enabling fine-grained adaptation and evaluation of RA policies on real hardware.
- Reward Function: We’ll design a reward function based on achieved throughput and transmission efficiency.
Learning: The agent updates its decision policy based on the rewards received, continuously improving its ability to choose optimal actions.
Training Strategy: We’ll apply experience replay, epsion-greedy exploration, and target network updates to stabilize training.
Evaluation: Compare performance against baseline algorithms like MInstrel-HT in both stable and mobile scenarios.
Setup
For the experimentation and evaluation of the DQN-based rate adaptation algorithm, I have access to two primary test environments:
- Local OpenWrt Setup
A pair of OpenWrt-based nodes is configured, one as an Access Point (AP) and the other as a Station(STA). This setup allows for short-range, controlled experiments where the data transmission between the AP and STA can be directly observed and influenced in real-time. The system logs transmission statistics such as throughput, retry rates, and modulation rates, which are essential inputs for the learning algorithm.
The basic setup is ideal for testing initial versions of the DQN agent, debugging learning behavior, and validating the integration with the Rateman interface.

Fig 3. Local Desk Setup
- Remote Shielding Box Environment
Additionally, a remote RF shielding box setup is available, which offers an advanced testing environment. The shielding box can emulate various wireless channel conditions by introducing configurable attenuation, effectively emulating mobility, interference, or range variations. This is particularly valuable for testing how well the DQN agent adapts to dynamic network environments.
Together, these setups provide a well-rounded experimentation environment. The local OpenWrt pair allows for fast prototyping, while the shielding box supports in-depth analysis under variable channel conditions. This ensures the project has ample experimental infrastructure to develop, test, and fine-tune the proposed Learning-based rate adaptation (RA)l algorithm.
Deliverables of The Project
The main outcomes of this GSoC project are :
- A modular, well-documented DQN-based Wi-Fi RA agent integrated into Rateman.
- A training and evaluation pipeline for testing the algorithm on real hardware using ORCA.
- Performance analysis comparing our method with standard algorithms in dynamic and static environments.
- A comprehensive technical report and user guide to help others replicate or extend this work.
What has been done until now?
So far, the initial groundwork for the project has been laid out, with the following accomplishments:
- Explored the fundamentals of Deep Q-Learning (DQN) by implementing and experimenting with standard reinforcement learning environments such as FrozenLake and CartPole. These helped build an intuitive understanding of how Q-learning and neural networks interact in dynamic decision-making problems.
- Familiarized with the ORCA API and RateMan interface
- Successfully set up the experimental testbed with a pair of OpenWrt nodes configured in AP-STA mode. This local setup has been validated for basic connectivity and is ready for integration and testing of learning-based algorithms.
- Studied the performance and limitations of existing ML-based rate adaptation (RA) papers to refine scope.
While the concrete architecture for integrating the DQN agent with real-world transmission feedback is still under development, the foundational components are in place. The next phase will focus on defining a robust training pipeline using txs statistics and determining how to feed real-time feedback into the learning loop.
What’s Next?
- Implement the DQN agent and environment class using PyTorch.
- Integrate the agent with Rateman to observe real-time transmission feedback.
- Begin training and hyperparameter tuning on experimental data.
- Evaluate performance and iterate over model improvements.
Conclusion
I’m incredibly excited to begin this project as part of GSoC 2025! By merging Reinforcement Learning with real-world Wi-Fi experimentation, this project aims to push the boundaries of rate adaptation in wireless networks. I hope this work contributes to more intelligent, efficient, and adaptable wireless systems, and I am looking forward to sharing updates as we move forward.
Feel free to reach out if you’re interested in the project or have any questions.
References
1. Pawar, S. P., Thapa, P. D., Jelonek, J., Le, M., Kappen, A., Hainke, N., Huehn, T., Schulz-Zander, J., Wissing, H., & Fietkau, F.
Open-source Resource Control API for real IEEE 802.11 Networks.
2. Yin, W., Hu, P., Indulska, J., & Portmann, M. (2020).
MAC-layer rate control for 802.11 networks: A survey. Wireless Networks
3. Queirós, R., Almeida, E. N., Fontes, H., Ruela, J., & Campos, R. (2021).
Wi-Fi Rate Adaptation using a Simple Deep Reinforcement Learning Approach. IEEE Access.
4. Karmakar, R., Chattopadhyay, S., & Chakraborty, S. (2022).
SmartLA: Reinforcement Learning-based Link Adaptation for High Throughput Wireless Access Networks. Computer Networks.
One thought on “GSoC 2025: Deep Q Network-based Rate Adaptation for Practical IEEE 802.11 Networks”